Cvičení 13 - Rmarkdown - výroba pdf a html
Jan Vávra
install.packages(c("rmarkdown", "knitr", "tinytex"))
library(rmarkdown)
library(knitr)
library(tinytex)
tinytex::install_tinytex()
# po těchto příkazech byli studenti schopni vytvořit PDF z NewFile > RmarkdownCo si zde představíme?
- jak pomocí Rmarkdownu vytvořit PDF či HTML,
- podrobný manuál lze nalézt zde.
Budete potřebovat nainstalovat balíčky rmarkdown a
knitr.
Rmarkdown
V záložce File > New File > R Markdown můžete založit
nový typ dokumentu s koncovkou .Rmd. Můžete si vybrat, zda
má být výstupní formát HTML či PDF, případně něco pokročilého. Soubor začíná
hlavičkou, kde si můžete upravit název, autora, datum, typ výstupu a
mnohem více. PDF či HTML vyrobíte stistknutím tlačítka Knit v
horní záložce, kde lze i vybrat typ výstupu.
Text, který volně píšete bude součástí výsledného dokumentu. Odstavce oddělíte prázdným řádkem. Seznamy v neočíslovaných bodech zapíšete pomocí hvězdiček takto (je třeba volný řádek):
- pro kurzívu obalte text ve hvězdičkách po obou stranách
nebo podtržítky,
- takto se přidá podbod,
- pro tlusté písmo obalte dvěma hvězdičkami nebo
zdvojenými podtržítky,
- další způsob přidání podbodu,
přeškrtnutý text,strojové písmozískáte obalením do “`” (používané pro Rkové příkazy či objekty).
Očíslované seznamy se musí začít číslem čí písmenem s tečkou a pak se číslují samy a správně:
- Odkazy na web se dají dělat pomocí dvojice hranatých a kulatých závorek:
- Komentáře lze dělat po vzoru HTML komentářů pomocí
<!--a-->:
- přičemž zkratková klávesa Ctrl+Shift+C pro komentování stále funguje.
- Do textu lze přidávat také matematické symboly ze základní \(\LaTeX\)ové výbavy:
- \(\sqrt{2\pi} = \int\limits_{-\infty}^{\infty} \exp\left\{-\frac{1}{2} (x - \mu)^2\right\} \, \mathrm{d}x\)
- \(\mathbf{X} \sim \mathsf{N}_3(\boldsymbol{\mu}, \boldsymbol{\Sigma})\)
- Stejně tak můžete přidávat i vycentrované rovnice: \[ \begin{aligned} x + y &= 15, \\ 3x - y &= 3. \end{aligned} \] Ve spolupráci s TeXem a upraveným nastavením lze rovnice i nějak očíslovat. Dokud není volný řádek tak text stále pokračuje v položce seznamu.
Až s volným řádkem se list ruší. Teď si ukážeme, jak se pracuje s nadpisy.
Hlavní nadpis
Podnadpis
Menší nadpis
Název pro odstavec
Ještě menší drobnost
Text miniaturním písmem, dál už to zmenšovat nejde
Vidíte?
Ovšem největší přínos Rmarkdownu tkví v inkluzi zdrojového kódu Rka
(a případně jiných jazyků). Základním místem, kam vkládat Rkový kód je
tzv. chunk. Lze jej vytvořit pomocí Ctrl+Alt+I nebo
kliknutím na +C v horní liště. Je vždy oddělen třemi symboly
“", což na české klávesnici je *Alt Gr + 7*. Následují složené závorky, ve kterých se udá, o jaký typ chunku jde, zder`
pro Rko:
x <- rnorm(1)
# komentáře zde fungují jako v klasickém Rkovém skriptu
# nadpisy chunku by měly být jedinečné a ideálně bez mezer (raději pomlčky)Do textu pak můžete vpisovat přímé výsledky pomocí apostrofů
začínajících písmenem r. Ku příkladu vygenerovaná hodnota x
byla 0.5048723, což zaokrouhleno na 3 platná číslice je 0.505.
Můžete si vytvořit i větu, která se automaticky upraví dle výsledku. Předem si připravíte proměnnou do nějaké proměnné (kód pak skryjete uživateli):
string <- paste0("Vygenerované číslo x = ", format(x, digits = 3), " je ",
ifelse(x < 0, "záporné", "kladné"), ".")A teď jen do textu vepíšete Vygenerované číslo x = 0.505 je kladné.. Vyzkoušejme. Vygenerované číslo x = 0.505 je kladné.
Každý chunk má spoustu nastavení, které do hlavičky můžete zadat,
abyste upřesnili, co se má stát s Rkovým kódem. Nejužitečnější je skrytí
zdrojového kódu pomocí echo:
Teď je hodnota x rovna 0.255, ale čtenář dokumentu to
neuvidí.
Tohle je ukázka neprovedeného zdrojového kódu (nemusí být ani
funkční) pomocí eval:
x <- 3Kód se ukáže čtenáři, ale hodnota x je stále 0.255.
Ve výsledném dokumentu je vždy zobrazeno veškeré tisknutí, které tříští kód a výsledek:
x## [1] 0.254896summary(rnorm(50))## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -2.27952 -0.90397 -0.07408 -0.16322 0.55628 1.44274Pokud nechceme výsledky vidět, můžeme to zakázat pomocí
results:
summary(rnorm(50))
log(-3)## Warning in log(-3): NaNs producedOvšem varovné hlášky to stále ukazuje. Pokud tomu chceme předejít,
tak musíme upravit warning:
log(-5)
library(mixAK)## Loading required package: lme4## Loading required package: Matrix##
## ### Mixture of methods including mixtures
## ### Arnost Komarek
##
## ### See citation("mixAK") or toBibtex(citation("mixAK")) for the best way to cite
## ### the package if you find it useful.Jak je vidět, načítání knihoven či používání funkcí občas vypisuje
nechtěný text. K tomu je nutné ještě přidat další nastavení pro
message:
log(-5)
library(car)Všechna tyto hlavičková nastavení chunku mají své defaultní hodnoty, které lze přenastavit pomocí:
knitr::opts_chunk$set(warning = FALSE, message = FALSE) # pro přehlednost raději nahoře v úvodu souboruTeď už by to vždy mělo zamezit tisknutí nechtěných zpráv:
log(-10)## [1] NaNfig_dir <- file.path(dirname(getwd()), "fig")Spousta parametrů je určena obrázkům. Lze tu přenastavit velikost, zarovnání, popisky atd.
x <- runif(50)
y <- 1 - x + rnorm(50)
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(x, y, bg = "lightblue", col = "blue", pch = 21)
abline(1, -1, col = "red", lty = 1)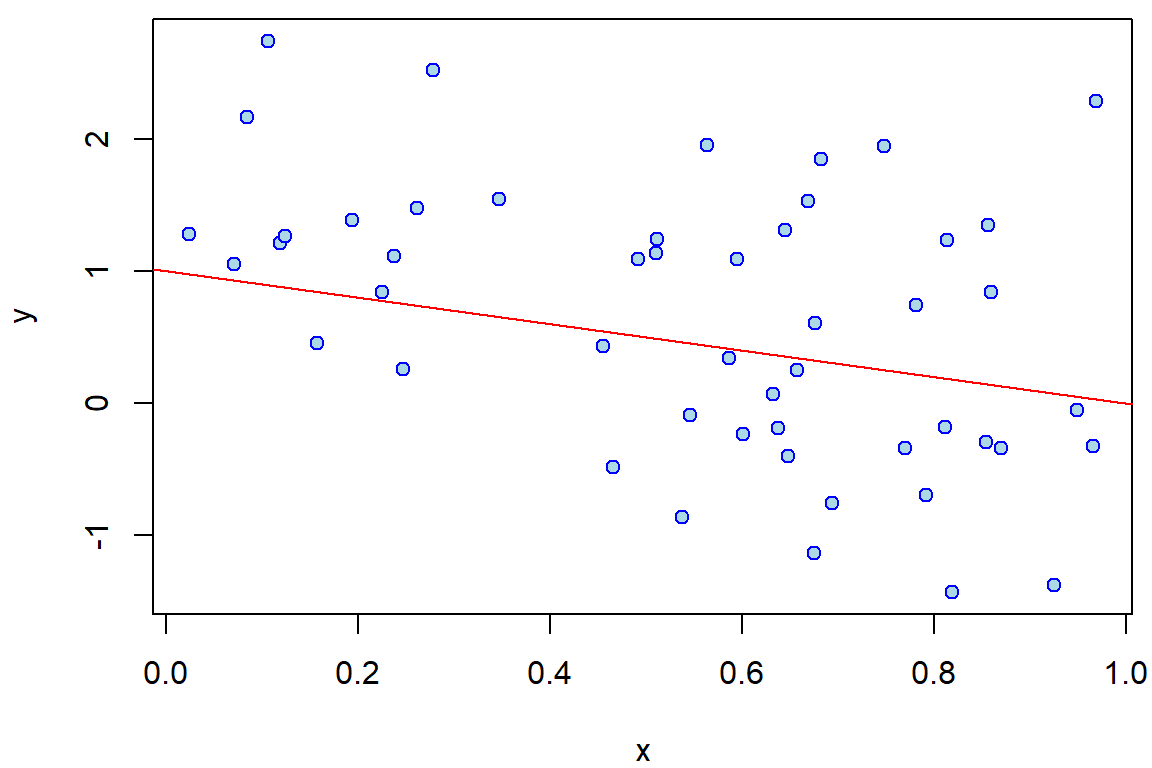
Scatterplot \(x\) a \(y\).
Pomocí fig.keep či fig.show můžete zakázat
vykreslovaným obrázkům, aby se ve výsledku objevily:
hist(x)
Histogramy \(x\) a \(y\).
hist(y)Obrázek se dá uložit rovnou pomocí těchto chunk nastavení pomocí
fig.path, přičemž se uloží pod názvem chunku, v případě
většího počtu doplněn ještě o pořadí určené písmeny:
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(x, y, bg = "lightblue", col = "blue", pch = 21)
abline(1, -1, col = "red", lty = 1)
Scatterplot \(x\) a \(y\).
Pokud máte problémy se zobrazením české diakritiky (zejména při
tvorbě PDF), tak použijte v hlavičce chunku
fig.format="CairoPNG" či jiný Cairo typ
výstupu. Je třeba si stáhnout a zahrnout knihovnu
library("Cairo"). Další možnost je nastavit si pomocí
funkce knitr::opts_chunk$set(dev = 'cairo_pdf') defaultní
nástroj pro tvorbu obrázků. Nebo si obrázky nejprve uložte pomocí
cairo_pdf() a pak vložte do textu.
Takto lze vložit již vytvořený obrázek:
 Případně ještě takto přímo do textu:
Případně ještě takto přímo do textu: 
Nebo si lze udělat referenci k obrázku, kterou uvedeme na samotném konci souboru:

Tabulku lze stvořit hezky manuálně pomocí čar a pomlček:
| První nadpis | Druhý nadpis |
|---|---|
| obsah | 1.23 |
| obsah | 5.35 |
Ale nejlépe se dělá pomocí funkce kable:
kable(head(iris))| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
Na těchto
stránkách se pak dozvíte více o tvorbě tabulek a funkce
kable.
Na závěr si už jen řekneme, jak jsem celou dobu vytvářel z Rmd souborů Rkové skripty:
knitr::purl(paste0("cviceni_", x, ".Rmd"), documentation = 2) # podívejte se na jiné volby documentationZde na konci souboru vypíšeme přehled všech id, který nebude viditelný pro čtenáře: