Cvičení 10 - Kreslení obrázků
Jan Vávra
Rkový skript ke stažení: R
Co si zde představíme?
- základní parametry pro
plot, - základní typy grafů dle typu proměnných,
- kreslení pomocí
ggplot2, - ukládání obrázků a další užitečné tipy.
Úvodem bych chtěl varovat, že obrázky jsou velmi silný nástroj, který
čtenáře zaujme jako první. Snahou o hezkou a názornou vizualizaci si
můžete snadno získat jeho přízeň a chuť číst dále. Ovšem buďte na
pozoru, neboť pomocí obrázků se dá snadno lhát:
Tento dokument obsahuje přehled názvů barev v Rku.
Funkce plot, její parametry a základní kreslící
funkce
Základní funkce, která umožňuje zakreslovat data do dvourozměrného
obrázku je plot(). Její výstup se často velmi liší podle
toho, jakým způsobem jsou zadána data. V této části budeme pracovat s
numerickými hodnotami x a y a v další části si
ukážeme více. V tomto případě nám Rko vrátí bodový diagram:
n <- 100
x <- rnorm(n)
y <- 1 - x + rnorm(n, sd = 0.5)
plot(x, y) Asi se shodneme, že takovýto graf zrovna vábně nevypadá. Můžeme si
polepšit upřesněním spousty argumentů, začněme s těmi přímočarými.
Asi se shodneme, že takovýto graf zrovna vábně nevypadá. Můžeme si
polepšit upřesněním spousty argumentů, začněme s těmi přímočarými.
plot(x, y,
xlab = "Náhodná veličina X", ylab = "Náhodná veličina Y", main = "Závislost Y na X", # popisky
pch = 18, col = "skyblue", cex = 0.7 # symbol, barva a velikost bodu
)
# ?pch # pro vysvětlení čísel symbolůpar v sobě ukrývá současné nastavení parametrů pro
vykreslování obrázků. Pokud se Vám třeba nelíbí ta spousta volného místa
okolo grafu, tak přenastavte mar:
par(mar = c(4, 4, 2, 0.5)) # počet "linek" v pořadí bottom, left, top, right
# odteď bude platné pro všechny následující obrázky, dokud se nezmění
plot(x, y,
xlim = c(-3, 3), ylim = c(-2, 5), # dolní a horní limity pro x-ovou a y-ovou osu
xlab = "Náhodná veličina X", ylab = "Náhodná veličina Y", main = "Závislost Y na X",
pch = 23, col = "darkblue", bg = "deepskyblue", cex = 0.8 # symbol s vnitřním pozadím
)
# ?par # přehled všech nastavitelných parametrůProhledáním help(par) zjistíme, že jde upravit opravdu
mnohé:
par(mar = c(5.2, 4.2, 3, 0.5))
plot(x, y,
xlim = c(-3, 3), ylim = c(-2, 5), # dolní a horní limity pro x-ovou a y-ovou osu
xlab = "Náhodná veličina X", ylab = "Náhodná veličina Y",
main = "Závislost Y na X", sub = "Bodový diagram", # hlavní a sekundární popisek grafu
pch = 7, col = "orchid", cex = 0.8,
bty = "n", # žádný obdélník okolo dat, dále "o" (the default), "l", "7", "c", "u", "]"
cex.axis = 0.5, # menší čísla u os
col.axis = "darkgreen", # barva čísel na ose
font.axis = 2, # tučné písmo na ose
cex.lab = 1.2, col.lab = "darkblue", font.lab = 3, # nastavení popisků os
cex.main = 3, col.main = "chocolate", font.main = 2, # nastavení nadpisu
cex.sub = 0.7, col.sub = "slategrey", font.sub = 4 # nastavení sekundárního popisku
)
# ?par # přehled všech nastavitelných parametrůNyní se věnujme osám grafu. Pokud nejsme spokojeni s defaultním výstupem, můžeme zakázat jejich vykreslení a vložit osy vlastní:
par(mar = c(4, 4, 2, 2))
plot(x, y,
xlim = c(-3, 3), ylim = c(-2, 5),
xlab = "Náhodná veličina X", ylab = "", main = "Závislost Y na X",
pch = 23, col = "darkblue", bg = "deepskyblue", cex = 0.8,
xaxt = "n", # zamezí vykreslení osy x
yaxt = "n" # zamezí vykreslení osy y
)
axis(side = 1, at = seq(-3, 3, by = 0.5)) # vytvoření x-ové osy (je třeba nejprve zrušit výše)
axis(side = 4, at = seq(-2, 5, by = 1), las = 2) # vytvoření y-ové osy vpravo + natočení
# ?axis
# ?mtext
mtext("Závislá proměnná", side = 2, line = 0.5, cex = 0.8, font = 3, col = "slategrey") # připsání textu okolo
mtext("Náhodná veličina Y", side = 2, line = 2, cex = 1.5, font = 2) # line udává vzdálenost od hrany oblasti Pro zajímavost: Rko používá funkci
Pro zajímavost: Rko používá funkci pretty() pro určení
hezkých popisků os:
# ?pretty
pretty(x) # n = 5 ## [1] -3 -2 -1 0 1 2pretty(x, n = 10) # chtěný počet intervalů (může být lehce nedodrženo)## [1] -2.5 -2.0 -1.5 -1.0 -0.5 0.0 0.5 1.0 1.5 2.0pretty(x, n = 6)## [1] -3 -2 -1 0 1 2pretty(x, n = 6, min.n = 6) # vynutí minimálně 6 intervalů## [1] -3 -2 -1 0 1 2 3Všimněme si, že funkce plot() spouští vždy nové
vykreslovací plátno. Na toto plátno se pak dají pomocí různých funkcí
postupně vrstvit další obrazce:
par(mar = c(4, 4, 2, 2))
plot(x, y,
xlim = c(-3, 3), ylim = c(-2, 5),
xlab = "Náhodná veličina X", ylab = "", main = "Závislost Y na X",
pch = 23, col = "darkblue", bg = "deepskyblue", cex = 0.8,
yaxt = "n"
)
axis(side = 4, at = seq(-2, 5, by = 1), las = 2) # vytvoření y-ové osy vpravo + natočení
mtext(expression(Y == beta[0] + beta[1] * X + epsilon), # lze přidávat i řecká písmena a indexy
side = 2, line = 0.5, cex = 0.8, font = 3, col = "slategrey")
mtext("Náhodná veličina Y", side = 2, line = 2, cex = 1.3, font = 2) # line udává vzdálenost od hrany oblasti
# ?abline # přidává přímku do grafu
abline(a = 1, b = -1, col = "red", # červená přímka y = a + b * x
lty = 2, # 1=solid (default), 2=dashed, 3=dotted, 4=dotdash, 5=longdash, 6=twodash
lwd = 2) # tloušťka čáry
abline(h = 1, lty = 3, lwd = 0.7, col = "grey") # horizontální linka (skutečná střední hodnota)
abline(v = 0, lty = 3, lwd = 0.7, col = "grey") # vertikální linka (skutečná střední hodnota)
# ?points # přidání bodů
points(mean(x), mean(y), pch = 8, cex = 2, lwd = 2, col = "darkorchid") # přidání bodu (výběrový průměr)
# ?lines # přidání lineárních spojnic bodů
xbreaks <- c(-2.5, -1:1, 2.5)
xstredy <- zoo::rollmean(xbreaks, 2)
fx <- cut(x, breaks = xbreaks)
miny <- tapply(y, fx, min)
maxy <- tapply(y, fx, max)
lines(xstredy, miny, col = "goldenrod2", lwd = 3) # lokální minima y
lines(xstredy, maxy, col = "goldenrod4", lwd = 3) # lokální maxima y
# ?segment # přidání úseček (zde jen jedné)
segments(x0 = -3, x1 = 3, # výchozí a koncové x-ové souřadnice
y0 = 5, # y1 = y0, výchozí a koncové y-ové souřadnice
col = "firebrick", lwd = 1.5)
# ?rug # přidání "rohožky"
rug(x, col = "lawngreen", ticksize = 0.02)
# ?arrows # přidání šipek
arrows(x0 = -3, y0 = min(y), y1 = max(y), col = "peru", lwd = 2,
code = 3, # směr šipky: =1 (od 0 k 1), =2 (od 1 k 0), =3 (oba směry)
length = 0.1, angle = 70) # nastavení délky a úhlu šipek
arrows(x0 = -2, x1 = -1,
y0 = 0.5, y1 = -1, col = "red4", lwd = 2)
# ?text # přidání textu do obrázku
text(-2, 0.5, labels = "hustota N(0,1)", pos = 3, # pos = 3 znamená nahoru od vytyčených souřadnic
col = "red4", font = 2, cex = 0.8)
# ?rect # přidání obdélníků
fy <- cut(y, breaks = -2:5)
histy <- prop.table(table(fy))
rect(xleft = 3-histy, xright = 3,
ybottom = -2:4, ytop = -1:5,
col = paste0("grey", seq(80, 20, by = -10)), border = "gold", lwd = 1.5)
# ?polygon # mnohoúhelník, přičemž může být opravdu velmi mnoho
gridx <- seq(-3, 3, by = 0.05)
polyx <- c(-3, gridx, 3)
polyy <- 4*c(0, dnorm(gridx), 0) -2
polygon(x = polyx, y = polyy, col = "turquoise", border = "seagreen", lwd = 2)
# ?legend
legend("topleft",
c("Pozorování", "Průměr"),
ncol = 2, # počet sloupečků legendy
title = "Nadpis legendy", title.cex = 0.6,
cex = 0.8, # relativní velikost celé legendy
bty = "u", # styl rámečku okolo legendy
pch = c(23, 8),
col = c("darkblue", "darkorchid"),
pt.bg = c("deepskyblue", NA),
lwd = c(1, 2),
lty = 0
)
legend(0.1, 4, c("Podmíněná střední hodnota", "Marginální střední hodnota"),
col = c("red", "grey"), lty = c(2, 3), lwd = c(2, 1),
cex = 0.8, box.lty = 5)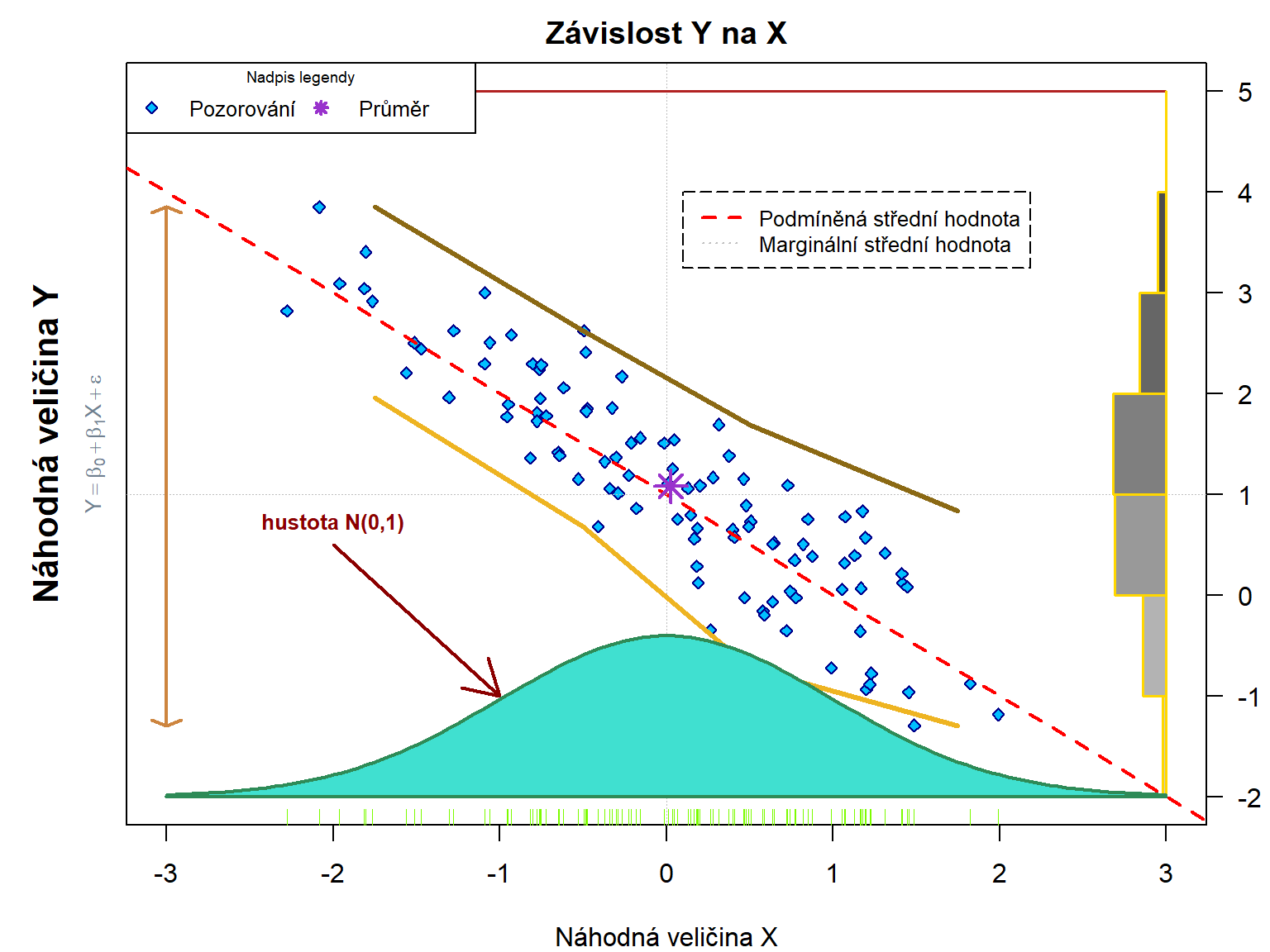 Pokud máme data uložená v nějakém
Pokud máme data uložená v nějakém data.frame, tak můžeme
souřadnice bodů udávat také takto:
data(iris)
iris$fSpecies <- factor(iris$Species)
mycol <- c("pink", "orchid", "darkorchid")
names(mycol) <- levels(iris$fSpecies)
par(mar = c(4,4,0.5,0.5))
plot(Sepal.Width ~ Sepal.Length, data = iris, # závislá ~ vysvětlující proměnná
pch = 16, col = mycol[fSpecies]) # barva dle druhu kosatce
legend("topright", levels(iris$fSpecies),
ncol = nlevels(iris$fSpecies),
pch = 16, cex = 0.8, col = mycol)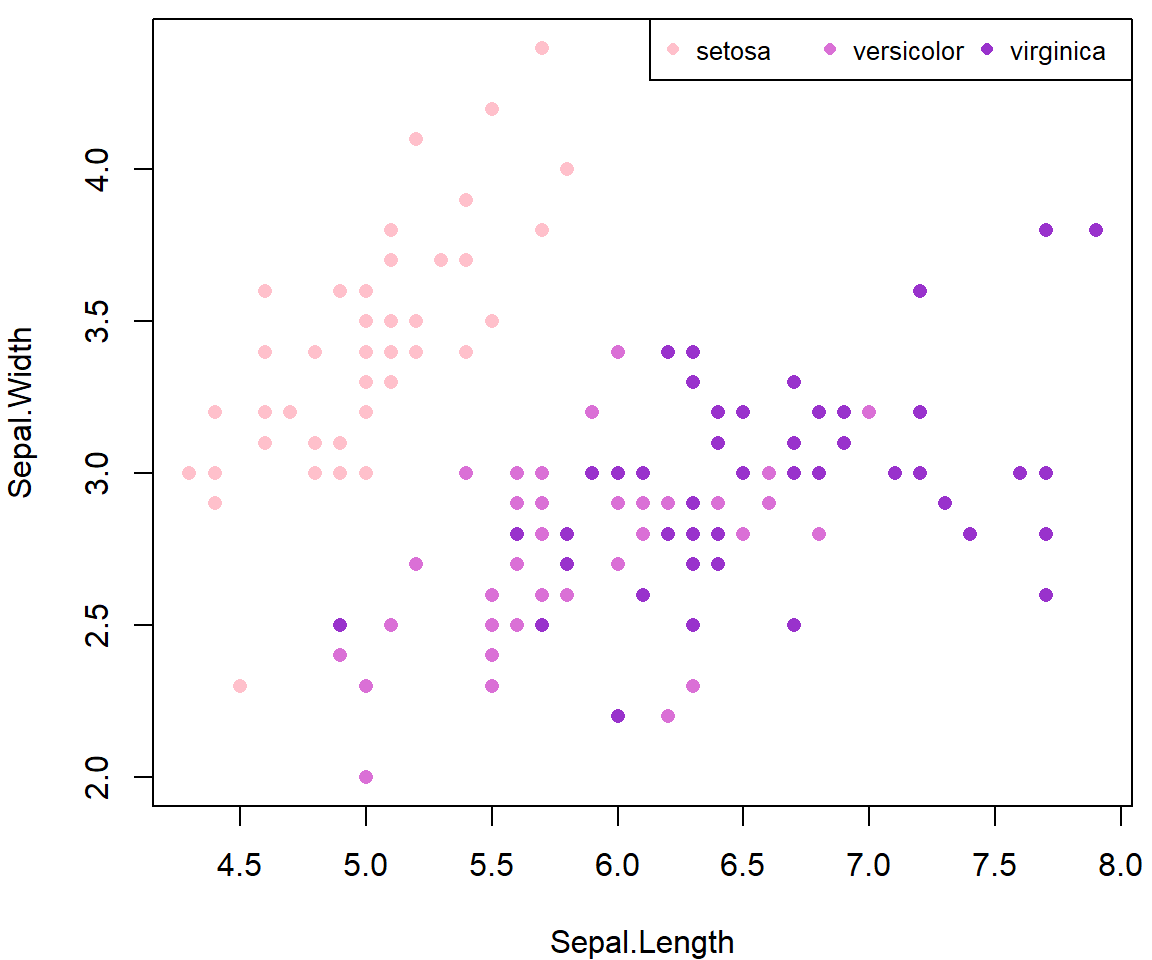
Někdy je užitečné použít logaritmické měřítko. Buď lze vykreslit
přímo log(x), ale takto lze zachovat popisky os v
originálním měřítku bez námahy:
data(Animals, package = "MASS")
summary(Animals)## body brain
## Min. : 0.023 Min. : 0.40
## 1st Qu.: 3.100 1st Qu.: 22.23
## Median : 53.830 Median : 137.00
## Mean : 4278.439 Mean : 574.52
## 3rd Qu.: 479.000 3rd Qu.: 420.00
## Max. :87000.000 Max. :5712.00par(mfrow = c(1,2), mar = c(4,4,2,0.5)) # dva obrázky vedle sebe
plot(brain ~ body, type = "n", data = Animals, # závislá ~ vysvětlující proměnná (žádné body)
main = "Animals - originální měřítko",
xlim = c(-2e4, 1.1e5), ylim = c(-2e2, 6e3))
text(Animals$body, Animals$brain, labels = rownames(Animals))
plot(brain ~ body, type = "n", data = Animals, # závislá ~ vysvětlující proměnná (žádné body)
main = "Animals - logaritmické měřítko",
log = "xy") # logaritmické transformace os x i y (popisky originální)
text(Animals$body, Animals$brain, labels = rownames(Animals)) # souřadnice nadále udávat v původním měřítku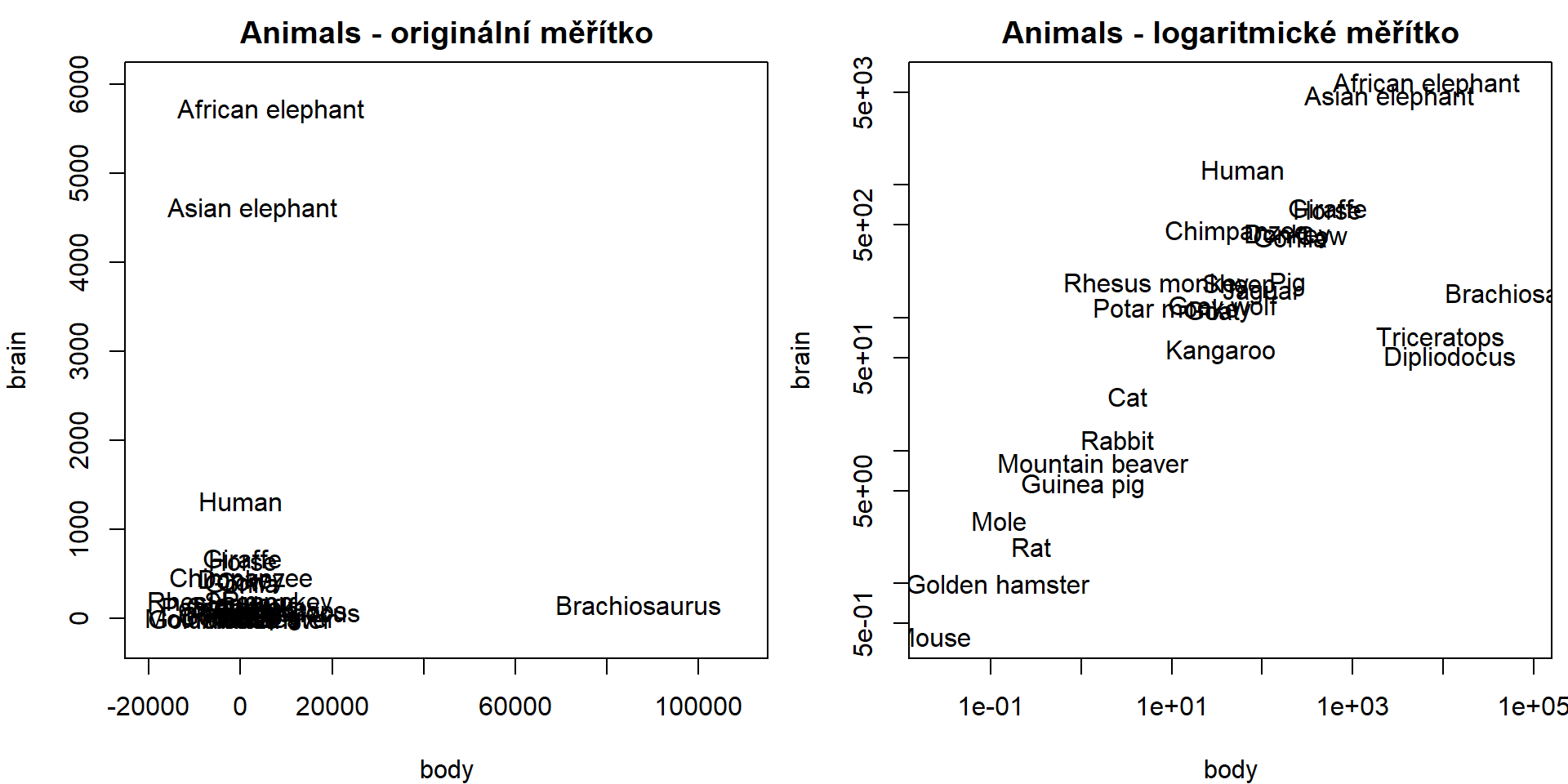
Základní typy grafů
Podívejme se nyní na různé varianty grafů, které Rko nabízí. Začněme
s tím, jak se mění výstup klasického plot při změně
type. Dávejte pozor, že některé mají smysl, jen když x-ové
hodnoty jsou srovnané od nejmenšího po největší:
par(mfrow = c(3,3), mar = c(2,2,2,0.5)) # mřížka 3×3 obrázků na jednom plátně
u <- 1:20
v <- rnorm(20)
plot(u, v, type = "n", main = "n") # "none" čisté plátno bez bodů
plot(u, v, type = "p", main = "p") # "points" jen body (defaultní nastavení)
plot(u, v, type = "l", main = "l") # "lines" lineární lomenná funkce
plot(u, v, type = "b", main = "b") # "both" body s úsečkami mezi nimi
plot(u, v, type = "c", main = "c") # přerušená lomenná čára na místě bodů
plot(u, v, type = "o", main = "o") # "over" body přes úsečky
plot(u, v, type = "s", main = "s") # "step" dolní skokovitá funkce (skok až s další hodnotou)
plot(u, v, type = "S", main = "S") # "Step" horní skokovitá funkce (skok hned s hodnotou)
plot(u, v, type = "h", main = "h") # "hist" vertikální linky jako histogram
Základní grafy pro práci s numerickou proměnnou jsou
boxplot, hist
par(mfrow = c(1,2), mar = c(4,4,2.5,0.5)) # mfrow = c(1,2) - mříž 1×2 pro obrázky (tedy dva vedle sebe)
boxplot(iris$Sepal.Length)
hist(iris$Sepal.Length)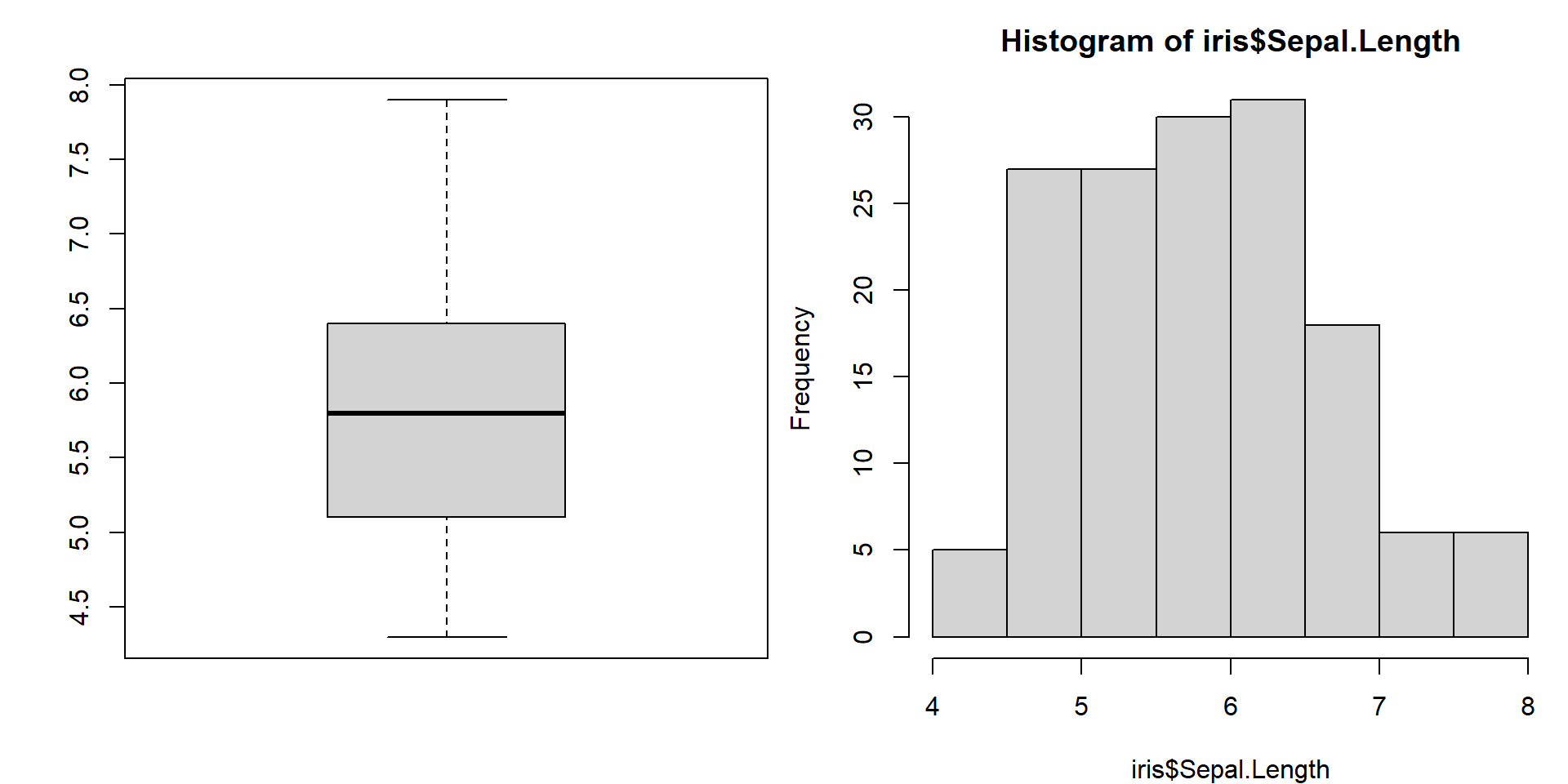
## Hezčí verze
par(mfrow = c(1,3), mar = c(2,4,2.5,0.5))
# Boxplot
boxplot(iris$Sepal.Length, main = "Sepal length [cm]", col = "tomato")
# Violin plot (je třeba nainstalovat balíček vioplot)
vioplot::vioplot(iris$Sepal.Length, main = "Sepal length [cm]", col = "goldenrod")
# využívá jádrové odhady hustoty jako
# plot(density(iris$Sepal.Length))
# ale nejdříve by to chtělo vědět, o co přesně se jedná...
hist(iris$Sepal.Length, xlab = "", main = "Sepal length [cm]", col = "lightblue",
freq = FALSE, # y-ovou osu jako hustotu (ne frekvence)
breaks = seq(4, 8, by=1/3), # vlastní dělení na intervaly
right = FALSE, # zleva uzavřené intervaly (namísto vpravo)
density = 20, # hustota šrafování
angle = 30, # úhel šrafování
border = "royalblue", # barva ohraničení
)
rug(iris$Sepal.Length, col = "red")
Vícero numerických proměnných lze zobrazit v matici bodovými diagramy stylem každý s každým:
# ?pairs
plot(iris[, 1:4]) # stejné jako funkce pairs(iris[, 1:4])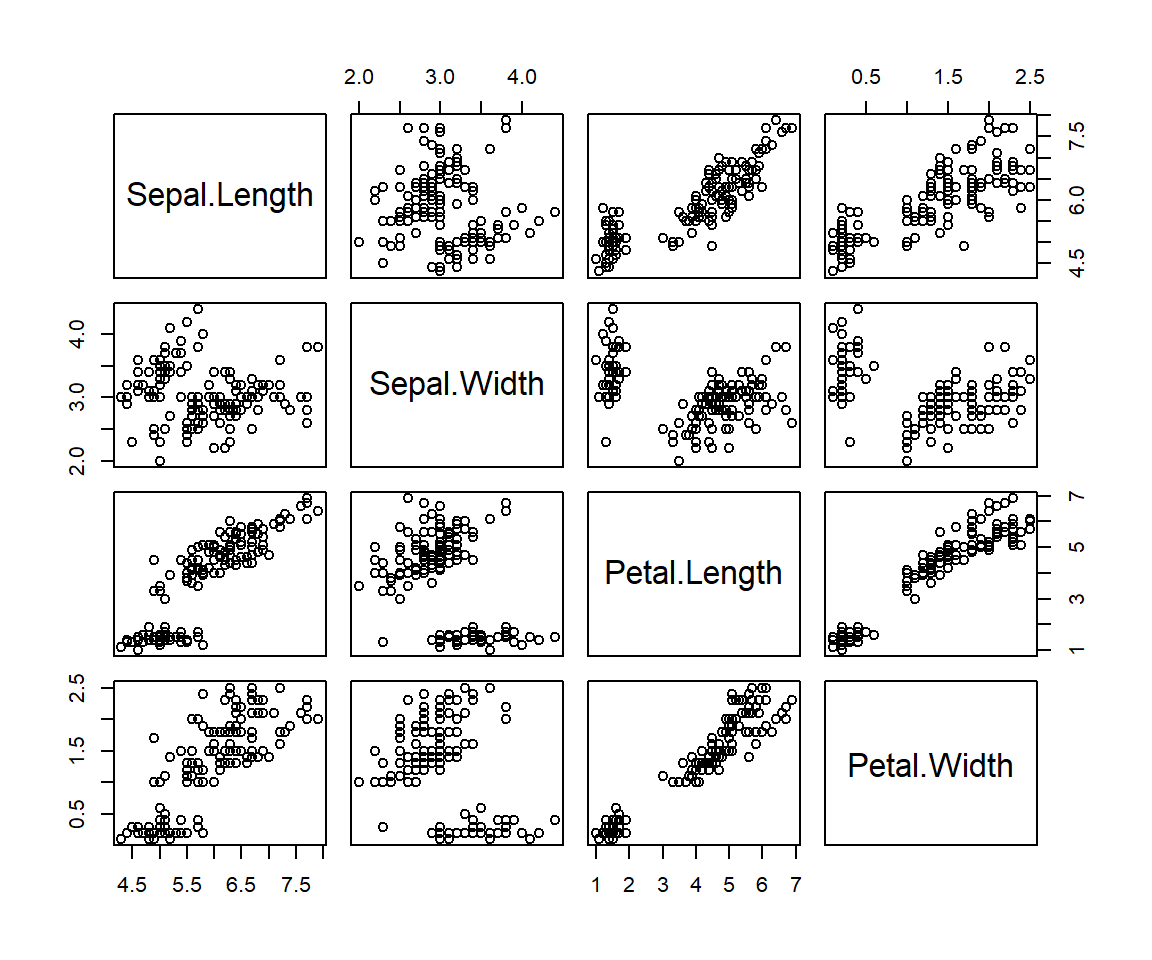
psych::pairs.panels(iris[, 1:4]) # hezčí verze z balíčku psych (je třeba nainstalovat)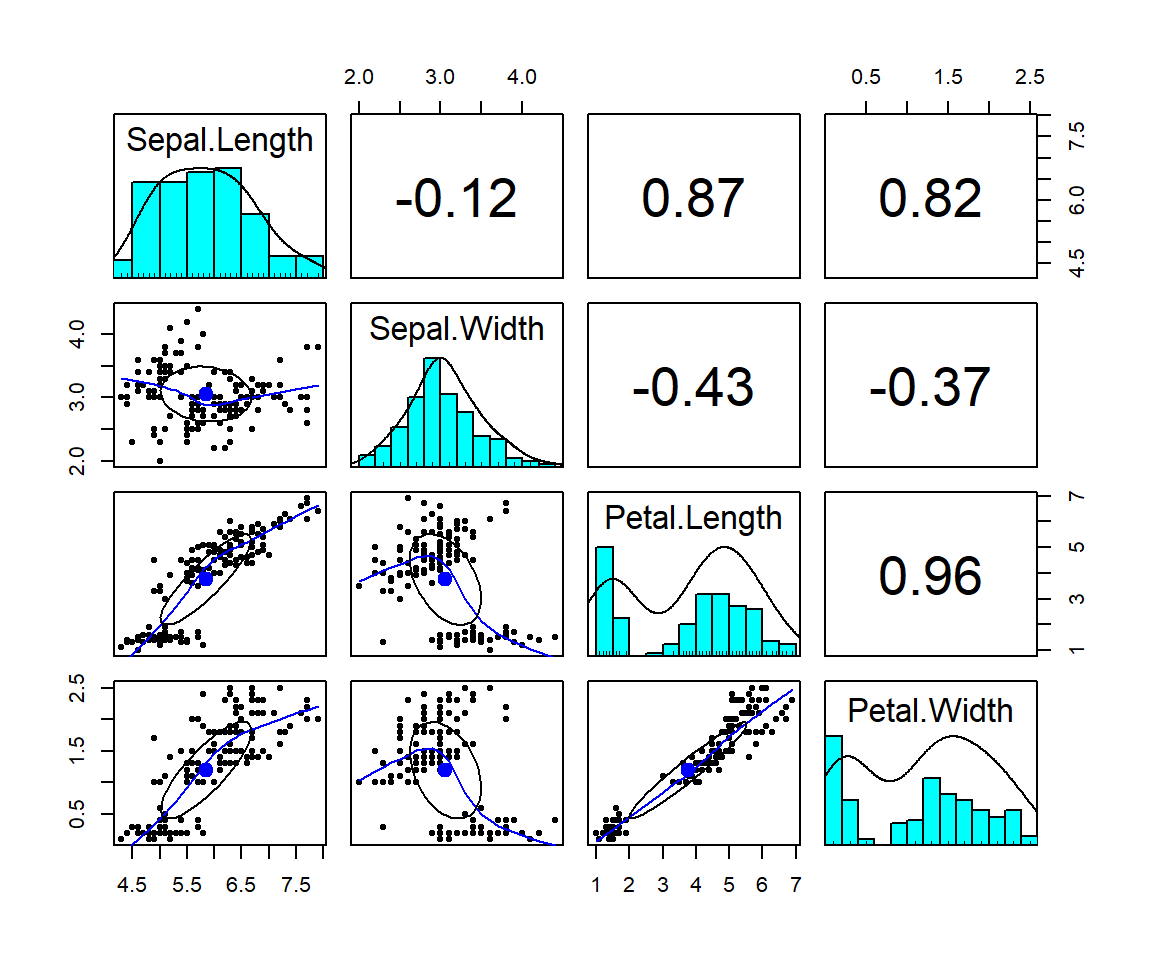
Nyní se zaměřme na kategoriální proměnné. Pro ně jsou vhodné
sloupcové (barplot) či koláčové (piechart)
grafy:
f <- factor(sample(1:3, 100, replace = T, prob = c(0.35, 0.45, 0.2)))
par(mfrow = c(2,2)) # mříž 2×2
plot(f) # = plot.factor --> vyprodukuje barplot
barplot(prop.table(table(f))) # očekává výšky sloupců tj. (relativní) četnosti
pie(table(f)) # očekává (relativní) četnosti
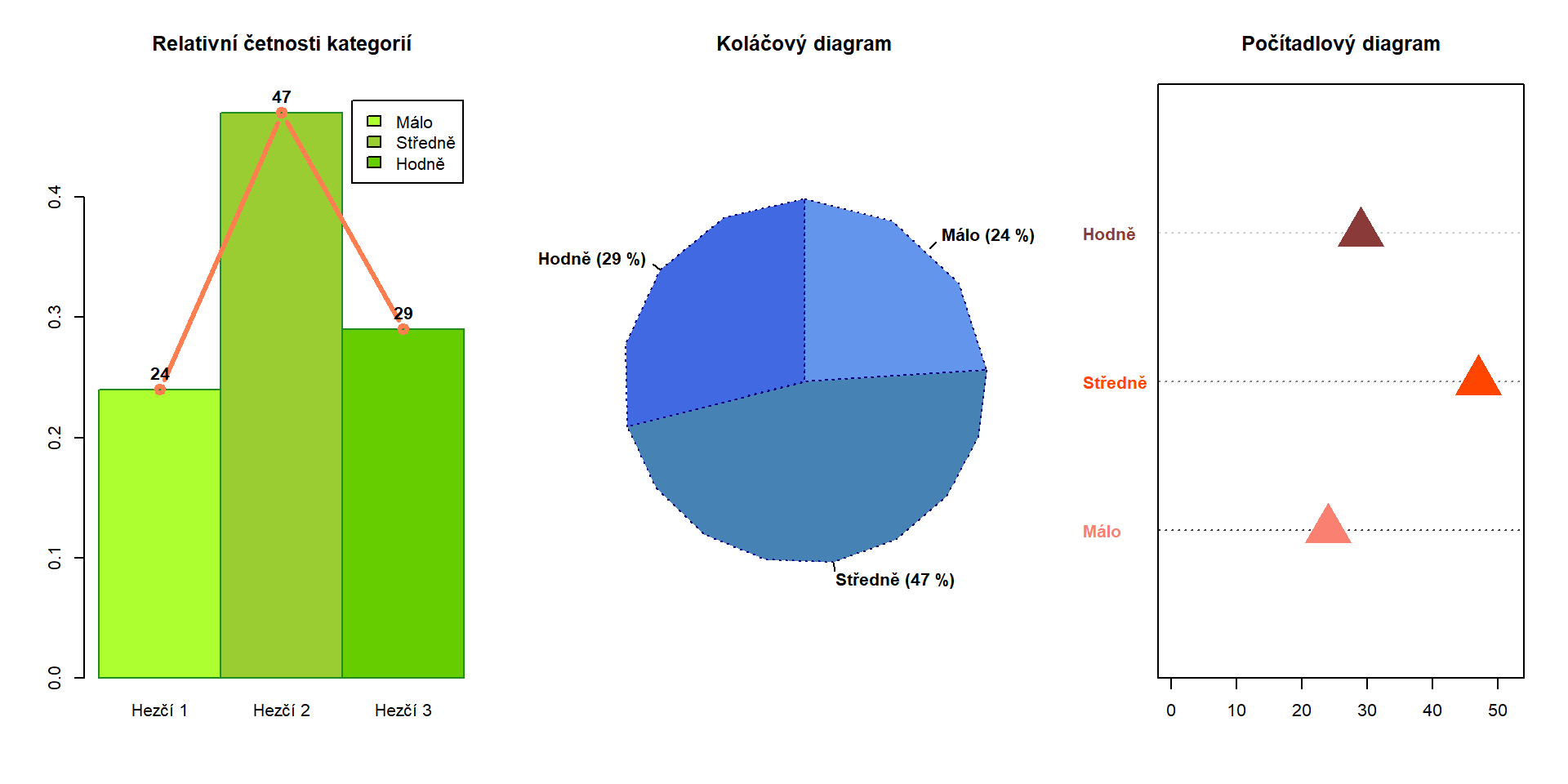
dotchart(table(f)) # srovnání kategorií bodově na liniích Zde je návod, jak si obrázky vyladit:
Zde je návod, jak si obrázky vyladit:
par(mfrow = c(1,3)) # mříž 2×2
pt <- prop.table(table(f))
b <- barplot(pt, width = 1, # šířka jedné kategorie
space = 0, # mezera mezi sloupci
main = "Relativní četnosti kategorií",
ylim = c(0, max(pt)*1.05), # navýšení horní hranice grafu
# horiz = TRUE, # vodorovné sloupce
names.arg = paste("Hezčí", 1:3), # přepíše levely faktoru na ose x
legend.text = c("Málo", "Středně", "Hodně"), # vytvoří legendu, pokud je třeba dovysvětlit
col = c("greenyellow", "yellowgreen", "chartreuse3"),
# density = 10, angle = 70, # šrafování místo úplné výplně
border = "forestgreen"
)
lines(seq(0.5, 2.5, by = 1), prop.table(table(f)), type = "b", col = "coral", lwd = 3)
# středy sloupců jsou díky nulovým mezerám mezi sloupci přesně 0.5, 1.5, 2.5 (zkuste bez udání space)
# Ovšem funkce nejen že kreslí, také (tiše) vrací středy sloupců.
# To můžeme využít třeba pro napsání číselné hodnoty nad sloupec.
text(b[,1], pt, labels = table(f), pos = 3, font = 2)
pie(table(f), edges = 20, # aproximace výseče pomocí polygonu o tolika stěnách
main = "Koláčový diagram",
radius = 1, # poloměr kruhu (pozor, kresleno do čtverce [-1,1]×[-1,1])
clockwise = TRUE, # zda začít jako hodiny na 12 a postupovat po směru hod. ručiček
labels = paste0(c("Málo", "Středně", "Hodně"),
" (", table(f) / length(f) * 100, " %)"),
# density = 30, angle = 50, # šrafování místo úplné výplně
col = c("cornflowerblue", "steelblue", "royalblue"),
border = "navyblue", lty = 3, font = 2
)
dotchart(table(f),
main = "Počítadlový diagram",
xlim = c(0, max(table(f))+5), # protáhnutí x-ové osy
labels = c("Málo", "Středně", "Hodně"), # popisky na levé straně
color = c("salmon", "orangered", "indianred4"), # barvy symbolů i popisků
pch = 17, pt.cex = 3, font = 2, # úprava symbolů, popisků
lcolor = c("grey20", "grey50", "grey80") # barvy linek
) 
Dvojice kategoriálních proměnných lze zakreslit následovně:
# Použijeme tabulku VADeaths dostupnou v Rku
# ?VADeaths
VADeaths## Rural Male Rural Female Urban Male Urban Female
## 50-54 11.7 8.7 15.4 8.4
## 55-59 18.1 11.7 24.3 13.6
## 60-64 26.9 20.3 37.0 19.3
## 65-69 41.0 30.9 54.6 35.1
## 70-74 66.0 54.3 71.1 50.0class(VADeaths)## [1] "matrix" "array"par(mfrow = c(2,2), mar = c(2.2,2.2,2,0.1))
barplot(VADeaths)
dotchart(VADeaths)
spineplot(VADeaths)
mosaicplot(VADeaths)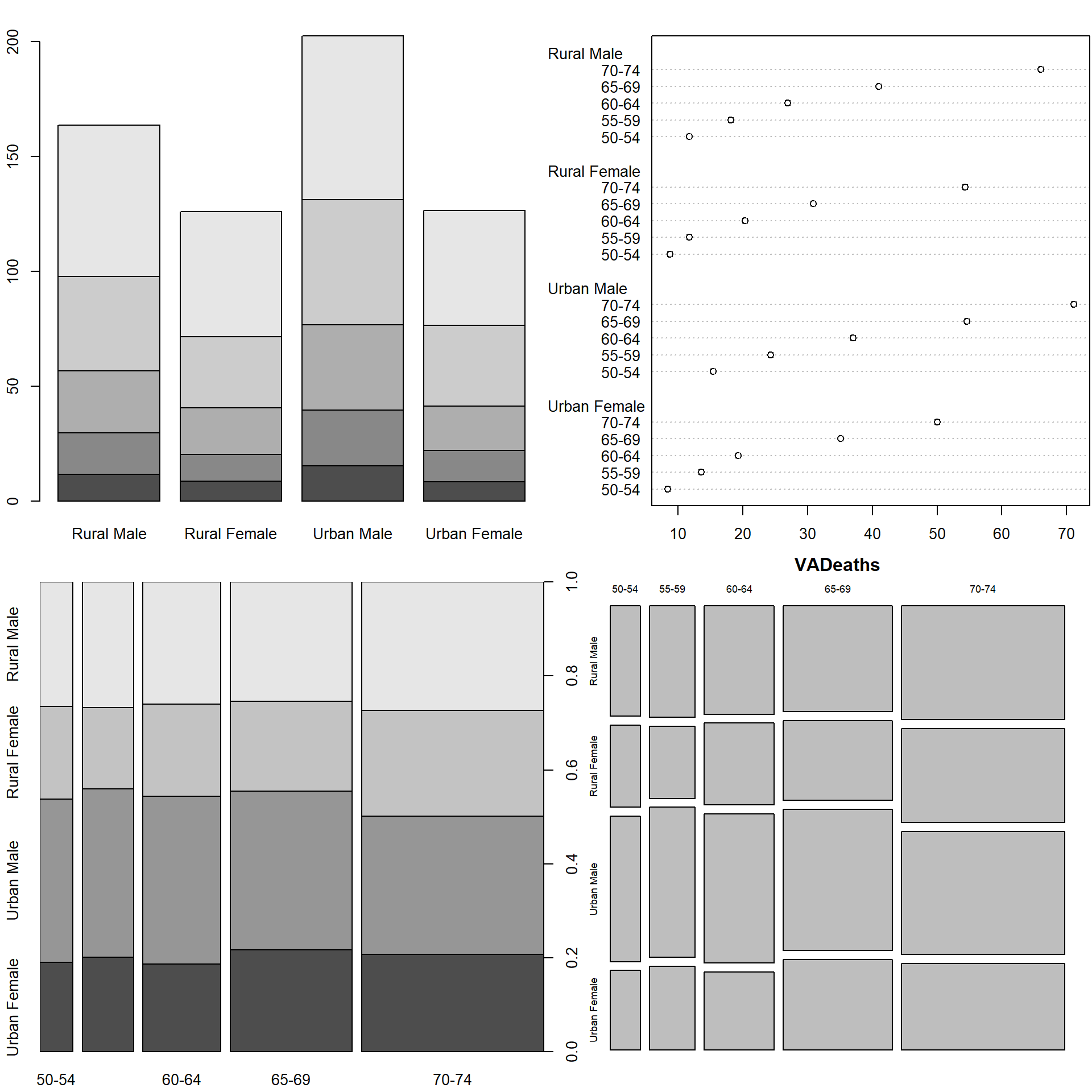
Opět si ukážeme, jak tyto obrázky oživit pomocí dodatečných parametrů:
library("car")
head(TitanicSurvival)## survived sex age passengerClass
## Allen, Miss. Elisabeth Walton yes female 29.0000 1st
## Allison, Master. Hudson Trevor yes male 0.9167 1st
## Allison, Miss. Helen Loraine no female 2.0000 1st
## Allison, Mr. Hudson Joshua Crei no male 30.0000 1st
## Allison, Mrs. Hudson J C (Bessi no female 25.0000 1st
## Anderson, Mr. Harry yes male 48.0000 1stsummary(TitanicSurvival)## survived sex age passengerClass
## no :809 female:466 Min. : 0.1667 1st:323
## yes:500 male :843 1st Qu.:21.0000 2nd:277
## Median :28.0000 3rd:709
## Mean :29.8811
## 3rd Qu.:39.0000
## Max. :80.0000
## NA's :263TitanicSurvival$fage <- addNA(cut(TitanicSurvival$age, breaks = c(0, 18, 35, 100),
labels = c("Child", "Young adult", "Older adult")))
# ?TitanicSurvival
(TAB1 <- table(TitanicSurvival$survived, TitanicSurvival$passengerClass))##
## 1st 2nd 3rd
## no 123 158 528
## yes 200 119 181(TAB2 <- table(TitanicSurvival$sex, TitanicSurvival$survived))##
## no yes
## female 127 339
## male 682 161(TAB3 <- table(TitanicSurvival$fage, TitanicSurvival$survived))##
## no yes
## Child 98 95
## Young adult 326 205
## Older adult 195 127
## <NA> 190 73(TAB4 <- table(TitanicSurvival$passengerClass,
TitanicSurvival$sex,
TitanicSurvival$survived ))## , , = no
##
##
## female male
## 1st 5 118
## 2nd 12 146
## 3rd 110 418
##
## , , = yes
##
##
## female male
## 1st 139 61
## 2nd 94 25
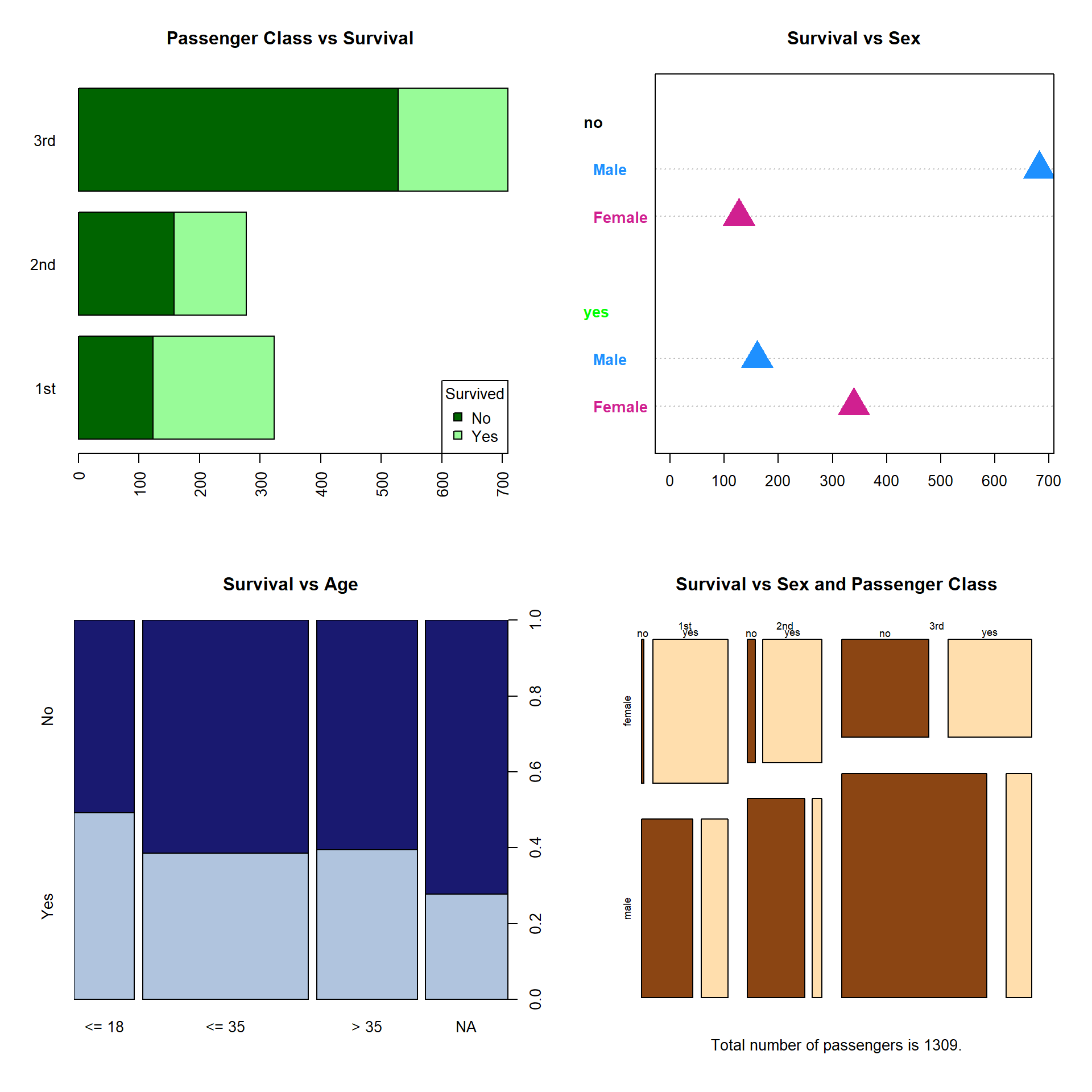
## 3rd 106 75par(mfrow = c(2,2))
barplot(TAB1, main = "Passenger Class vs Survival",
col = c("darkgreen", "palegreen"),
horiz = TRUE, las = 2)
legend("bottomright", c("No", "Yes"), title = "Survived",
pt.bg = c("darkgreen", "palegreen"), pch = 22, pt.cex = 1.3)
dotchart(TAB2, main = "Survival vs Sex",
xlim = c(0, max(TAB2)),
color = c("violetred", "dodgerblue"), # barvy podskupin a symbolů (zdola nahoru)
gcolor = c("black", "green"), # barvy hlavních skupin
pch = 17, pt.cex = 3, font = 2, # úprava symbolů, popisků
labels = c("Female", "Male") # úprava popisků
)
spineplot(TAB3, main = "Survival vs Age",
col = c("lightsteelblue", "midnightblue"), # barvy v pořadí odzdola nahoru
yaxlabels = c("No", "Yes"), # odshora dolů (tedy opačně!)
xaxlabels = c("<= 18", "<= 35", "> 35", "NA") # změna popisků
)
# mosaicplot zvládá i více jak dvourozměrné tabulky
mosaicplot(TAB4, main = "Survival vs Sex and Passenger Class",
col = c("saddlebrown", "navajowhite"), # barvy zleva doprava
# shade = T, # měří vychýlení od celkového průměru
sub = paste0("Total number of passengers is ", nrow(TitanicSurvival), ".") # menší titulek dole
)
Už jsme poznali, jak zakreslit samostatně numerické či samostatně kategoriální veličiny. Zbývá se zaměřit na případ kombinace těchto dvou kategorií. I když by rozdíl v pořadí mezi proměnnými být neměl, tak se v Rku rozlišují dva grafy dle typu vysvětlované proměnné. Když je naší odezvou numerická proměnná, výsledkem je soustava boxplotů, jeden pro každou kategorii:
par(mfrow = c(1,1), mar = c(4,4,2.5,2))
plot(count ~ spray, data = InsectSprays, # pomocí formule "y ~ x"
main = "InsectSprays",
col = c("bisque", "wheat", "ivory", "cornsilk", "beige", "honeydew")) 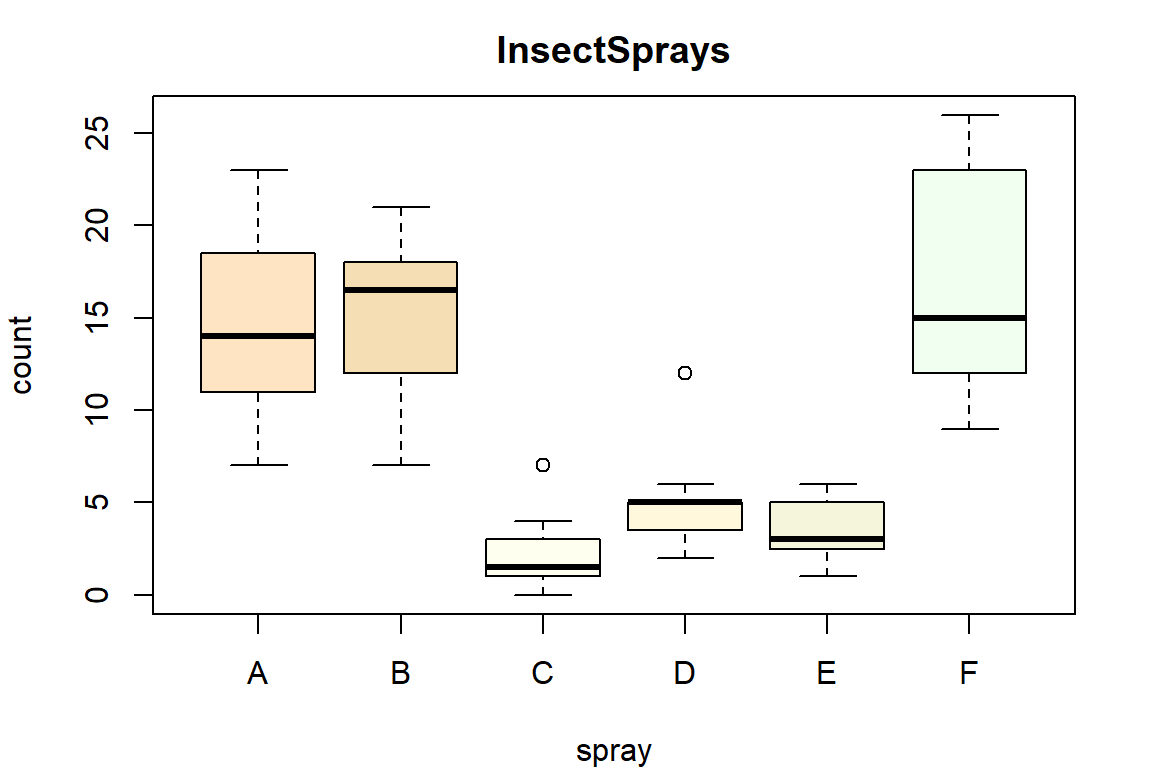
# odezva ~ závisí na těchto proměnných (takže první se píše y-ová osa, pak až x-ová)Můžeme tak sledovat, které kategorie mají k sobě blízko a které se od sebe liší.
Kategorizací numerické proměnné můžeme zakreslit vývoj vztahu.
data("Hosi0", package = "mffSM")
par(mfrow = c(1,2), mar = c(4,4,2.5,2))
plot(bweight ~ blength, data = Hosi0, # bez faktorizace jen bodový diagram
main = "Porodní váha a délka chlapců")
plot(bweight ~ factor(blength), data = Hosi0, # je třeba si faktor udělat
main = "Porodní váha a délka chlapců",
col = terrain.colors(9), # funkce vracející zadaný počet barev vhodný pro "výškový terén na mapě"
width = table(factor(blength))) # šířky boxplotů dle četnosti jednotlivých kategorií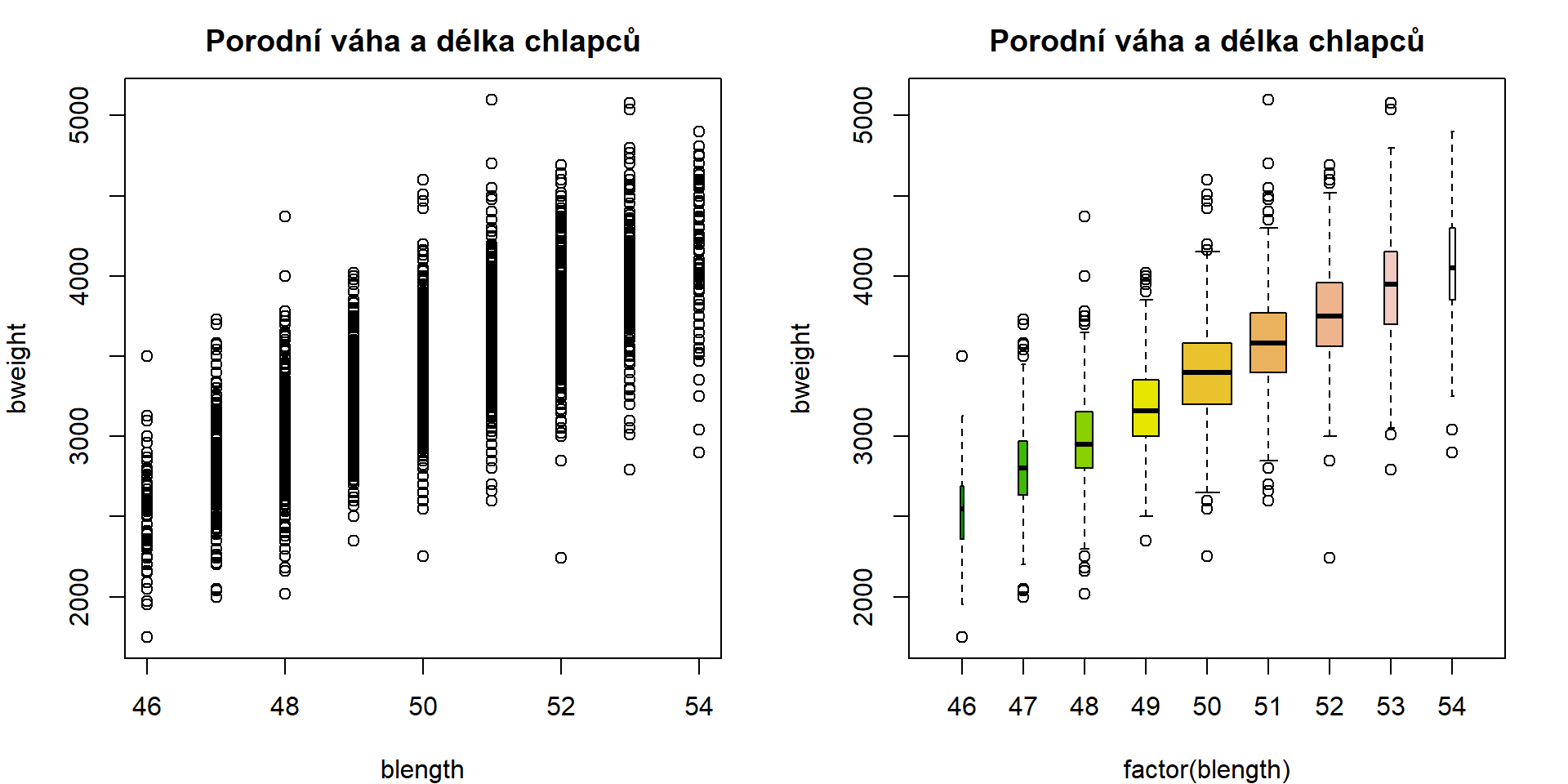
Jakmile je ale naší odezvou kategoriální proměnná a vysvětlující
numerická, nelze vykreslit boxploty. Numerická proměnná se vnitřně
kategorizuje pomocí cut s hezky ekvidistantně vzdálenými
dělícími body a vykreslí se spineplot znázorňující vývoj
poměrů kategorií se změnou numerické proměnné. Hraniční body nejsou od
sebe ekvidistantně vzdáleny, ale úměrně dle počtu pozorování v daném
intervalu.
par(mfrow = c(1,2), mar = c(4,4,2.5,2.5))
# defaultní výstup
plot(survived ~ age, data = TitanicSurvival)
# vlastní kategorie
plot(survived ~ age, data = TitanicSurvival,
breaks = c(0, 15, 20, 25, 30, 40, 50, 100), # vlastní kategorie
col = c("seashell", "darkslategrey")) 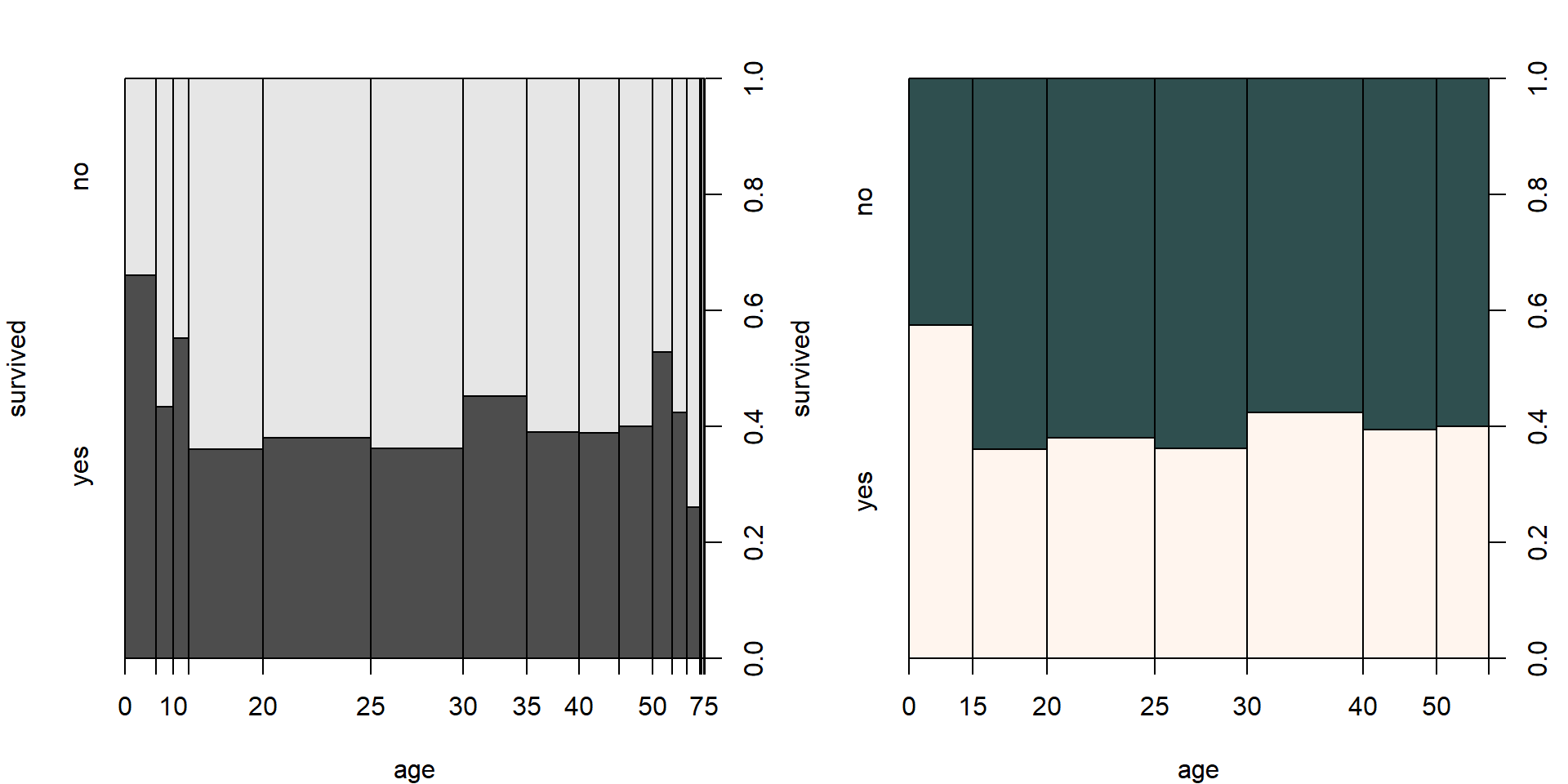
ggplot2
Doposud jsme si ukazovali kreslící funkce v základní výbavě Rka. V
poslední době (a hlavně komerční sféře) jsou oblíbené moderní Rkové
knihovny jako například ggplot2. Syntax kreslení je velmi
odlišný od toho standardního a má svou vlastní logiku:
library("ggplot2")## Use suppressPackageStartupMessages() to eliminate package startup messagesdata(diamonds, package = "ggplot2")
diamonds$fcarat <- cut(diamonds$carat, breaks = c(0,0.5,1,1.5,2,6))
gp <- ggplot(data = diamonds, # uložení obrázku do proměnné
mapping = aes(x = carat, y = price, color = clarity)) + # s jakými daty se pracuje
geom_point() # vykreslit body
gp # vykreslení současného stavu provede plot(gp) Obrázek máme uložený v proměnné
Obrázek máme uložený v proměnné gp a nyní k němu můžeme
přidat další příkazy upřesňující vzhled či další obrazce k
vykreslení:
grouped_diamonds <- matrix(tapply(diamonds$price, diamonds$clarity:diamonds$fcarat, mean),
nrow = nlevels(diamonds$fcarat))
rownames(grouped_diamonds) <- levels(diamonds$fcarat)
colnames(grouped_diamonds) <- levels(diamonds$clarity)
stredy <- c(0.25, 0.75, 1.25, 1.75, 4)
colors <- heat.colors(nlevels(diamonds$clarity))
gp2 <- gp + # přeuložení do jiné proměnné
geom_line(mapping = aes(x = stredy, I1), data = grouped_diamonds, color = colors[1], linewidth = 1.5) +
geom_line(mapping = aes(x = stredy, SI2), data = grouped_diamonds, color = colors[2], linewidth = 1.5) +
geom_line(mapping = aes(x = stredy, SI1), data = grouped_diamonds, color = colors[3], linewidth = 1.5) +
geom_line(mapping = aes(x = stredy, VS2), data = grouped_diamonds, color = colors[4], linewidth = 1.5) +
geom_line(mapping = aes(x = stredy, VS1), data = grouped_diamonds, color = colors[5], linewidth = 1.5) +
geom_line(mapping = aes(x = stredy, VVS2), data = grouped_diamonds, color = colors[6], linewidth = 1.5) +
geom_line(mapping = aes(x = stredy, VVS1), data = grouped_diamonds, color = colors[7], linewidth = 1.5) +
geom_line(mapping = aes(x = stredy, IF), data = grouped_diamonds, color = colors[8], linewidth = 1.5)
gp2 + theme_minimal() + # změna stylu obrázku
scale_x_log10() + # log10 transformace x
scale_y_log10() + # log10 transformace odezvy
labs(x = "Weight of the diamond [carat]",
y = "Price [$]",
title = "Scatterplot",
subtitle = "The price of diamonds vs weight and clarity on logarithmic scale")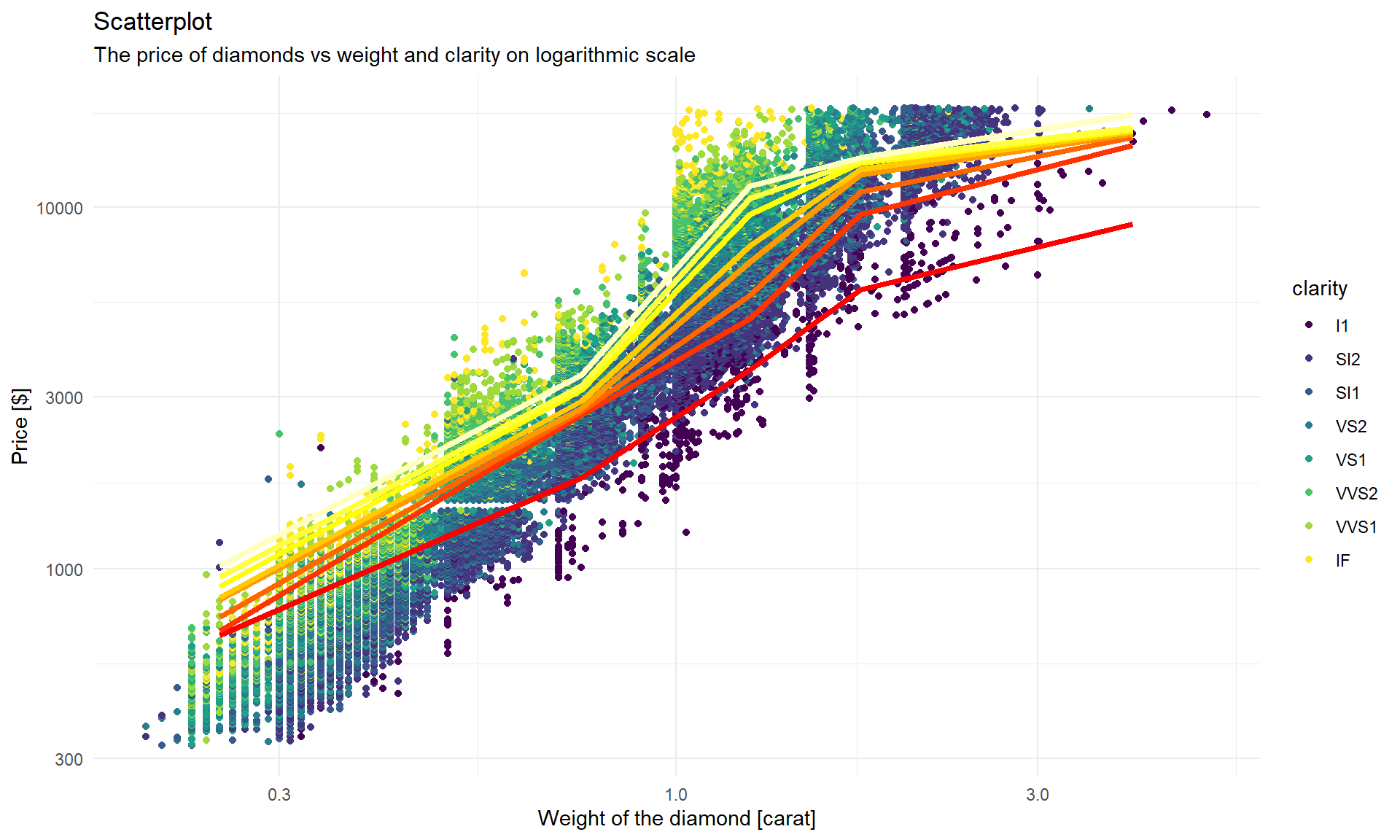 Jenže jak přidat legendu pro jednotlivé linky, když si legendu dělá
Jenže jak přidat legendu pro jednotlivé linky, když si legendu dělá
ggplot sám?
S ggplot2 se lze opravdu vyřádit, ale zde na to již není
prostor. Zde je odkaz na 50 zajímavých
obrázků i se zdrojovým kódem. Zde je odkaz na tvorbu
animovaných obrázků (pro prezentace či web) s pomocí knihovny
gganimate.
Ukládání obrázků a další užitečné tipy
Nyní se zaměřme na ukládání obrázků. Jedna (velmi nedoporučovaná!)
volba je záložka Plots > Export, kde si lze vybrat formát,
rozměry a kam se má obrázek uložit. Jenže při každé změně jednoho
obrázku hodláte znovu nastavovat to samé? Lepší je si ukládání obrázku
zaznamenat přímo do scriptu. Rko nabízí funkce pdf,
jpeg, png a další pro ukládání obrázků v
zadaném formátu.
Ukážeme si jejich použití spolu s dalšími kreslícími funkcemi, na které se zatím nedostalo.
WD <- getwd()
dir_fig <- file.path(dirname(WD), "fig") # upravte si dle vlastního adresáře
pdf(file = file.path(dir_fig, "sin_a_cos.pdf"),
width = 6, height = 4 # v palcích (inch)
# encoding = "utf8" # kódování znaků
)
{ # doporučuji všechny příkazy obalit
par(mfrow = c(1, 1), mar = c(4, 2, 2.5, 0.5)) # 1×1, okraje
curve(sin(x), from = -10, to = 10, col = "blue", lwd = 2, # vykreslí zadanou funkci v jedné proměnné
xlab = "x", ylab = "", main = "Goniometrické křivky") # klasické pdf má problém s českými znaky
# je třeba si vyhrát s encoding či fonts argumenty...
curve(cos(x), from = -10, to = 10, col = "red", lwd = 2, add = T) # add=T přidá do již existujícího obrázku
abline(h = 0, col = "grey", lty = 2)
abline(v = 0, col = "grey", lty = 3)
}
dev.off() # uzavření PDFka - NEZAPOMENOUT!!!Všimněte si, že české symboly se v Rku neuložily správně. Pro české
účely je daleko spolehlivější pokročilá verze této funkce
cairo_pdf():
cairo_pdf(file = file.path(dir_fig, "dnorm_dt.pdf"), width = 6, height = 4) # v palcích (inch)
{
par(mfrow = c(1, 1), mar = c(4, 4, 2.5, 0.5))
curve(dnorm(x), from = -3, to = 3, col = "blue", lwd = 2, # hustota N(0,1)
xlab = "x", ylab = "Hustota",
main = "Příliš žluťoučký kůň úpěl ďábelské ódy") # pro ověření češtiny
curve(dt(x, df = 5), from = -3, to = 3, col = "red", lwd = 2, add = T) # hustota t(5)
abline(h = 0, col = "grey", lty = 2)
abline(v = 0, col = "grey", lty = 3)
legend("topright", c("N(0,1)", "t(5)"), col = c("blue", "red"), lty = 1, lwd = 2)
}
dev.off() # uzavření PDFka - NEZAPOMENOUT!!!Další formát, ve kterém je možné obrázky ukládat je jpg.
Problém je však s kvalitou a velikostí obrázku:
x <- rnorm(50)
y <- rnorm(50, sd = 2)
jpeg(file.path(dir_fig, "ecdf.jpg"),
width = 1000, height = 700, units = "px", # v pixelech (jako default, ale lze změnit)
quality = 75, pointsize = 12 # originální nastavení kvality obrazu
)
{
layout(matrix(c(1,1, # první řádek splyne v jediný obrázek
2,3), nrow = 2, byrow = TRUE)) # mříž 2×2
par(mar = c(4,4,2.5,0.5))
# ?plot.ecdf # Empirická kumulativní distribuční funkce
# ?plot.acf # Empirická autokorelační funkce
plot(ecdf(x), col = "red", main = "Empirická distribuční funkce",
xlim = range(c(x, y))) # aby šíře okna pojala oba výběry
plot(ecdf(y), col = "blue", add = T)
plot(ecdf(x), col = "red", verticals = T, col.01line = "slategrey", pch = 19, main = "N(0,1)")
plot(ecdf(y), col = "blue", verticals = T, col.01line = "slategrey", pch = 16, main = "N(0,2^2)")
}
dev.off() # uzavření jpeg - NEZAPOMENOUT!!!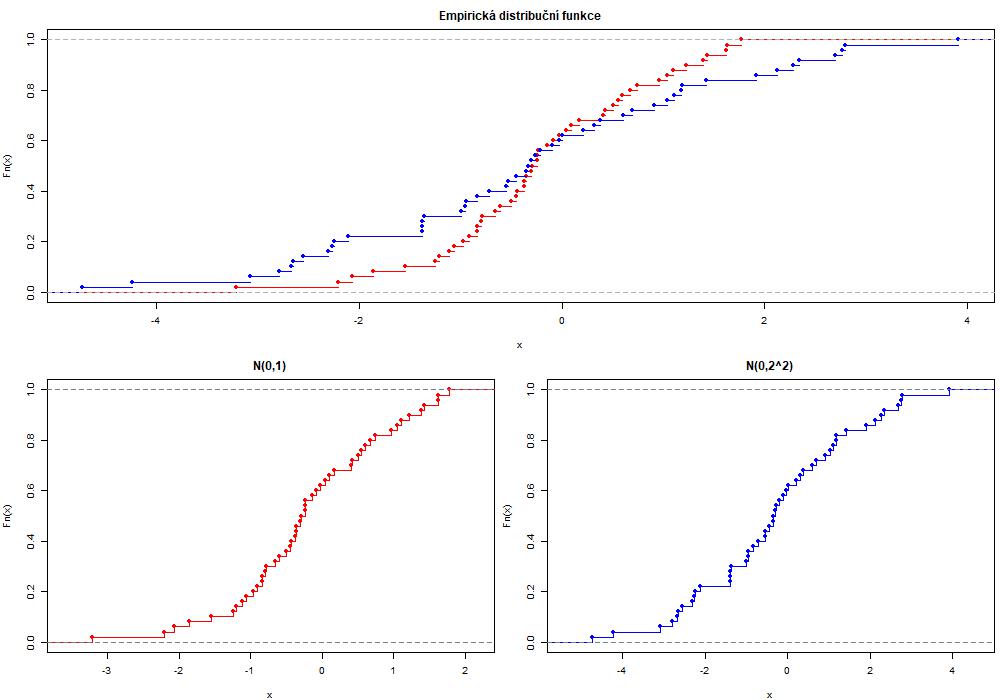
Kvalita velikost obrázku se dá navýšit hraním si s dodatečnými argumenty:
jpeg(file.path(dir_fig, "ecdf_kvalitneji.jpg"),
width = 1000, height = 700, units = "px", # stejné rozměry jako předtím
quality = 100, pointsize = 20 # zlepšení kvality obrázku + zvětšení písma,
# res = ... # rozlišení, 72 je default
)
{
layout(matrix(c(2,3, # mříž 2×2
1,1), nrow = 2, byrow = TRUE)) # druhý řádek splyne v jediný obrázek - ten první!
par(mar = c(4,4,2.5,0.5))
plot(ecdf(x), col = "red", main = "Empirická distribuční funkce",
xlim = range(c(x, y))) # aby šíře okna pojala oba výběry
plot(ecdf(y), col = "blue", add = T)
plot(ecdf(x), col = "red", verticals = T, col.01line = "slategrey", pch = 19, main = "N(0,1)")
plot(ecdf(y), col = "blue", verticals = T, col.01line = "slategrey", pch = 16, main = "N(0,2^2)")
}
dev.off() # uzavření jpeg - NEZAPOMENOUT!!!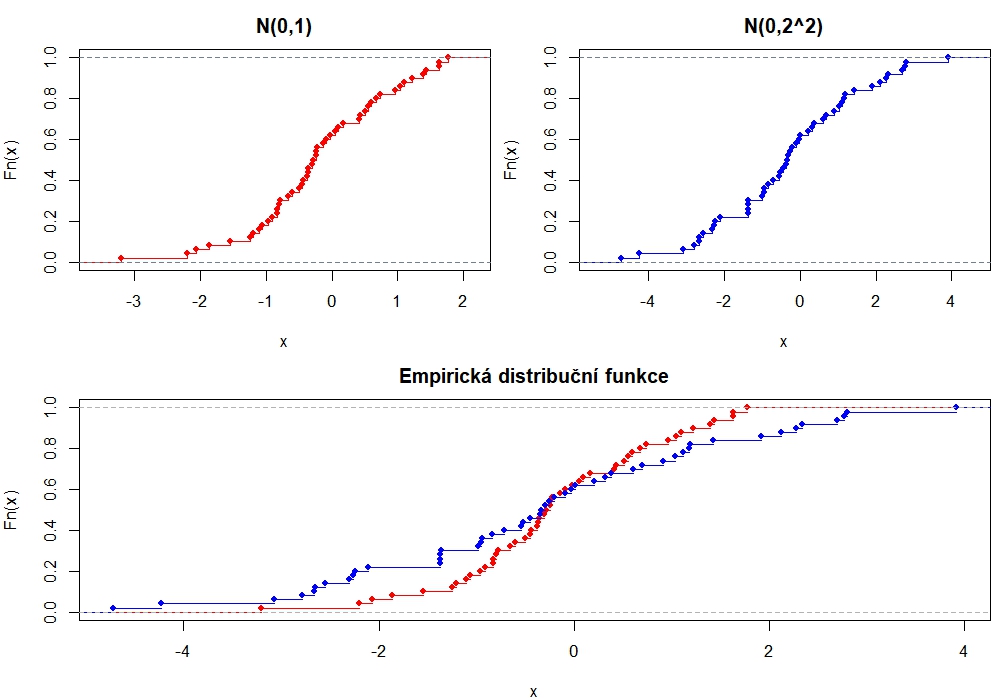
Dále lze ukládat jako png se stejnými argumenty jako
funkce jpeg:
y <- x <- seq(-2*pi, 2*pi, length.out = 201) # x-ové a y-ové hodnoty
z <- outer(sin(x), cos(y)) # z = sin(x) * cos(y), každý s každým
dim(z)
breaks <- seq(-1, 1, length.out = 11) # zkuste vyšší hodnoty, třeba 51
COLs <- terrain.colors(length(breaks)-1) # barev o 1 méně než
# ?terrain.colors # jaké další barevné palety Rko nabízí?
# COLs <- hcl.colors(length(breaks)-1, palette = "viridis")
# COLs <- hcl.colors(length(breaks)-1, palette = "Dark 3")
# COLs <- hcl.colors(length(breaks)-1, palette = "YlGnBu")
# COLs <- hcl.colors(length(breaks)-1, palette = "Green-Brown")
# COLs <- hcl.colors(length(breaks)-1, palette = "Blue-Red 3")
# COLs <- rainbow(length(breaks)-1)
# COLs <- heat.colors(length(breaks)-1)
# COLs <- topo.colors(length(breaks)-1)
# COLs <- cm.colors(length(breaks)-1)
png(file.path(dir_fig, paste0("image_sincos_", length(breaks)-1, "_barvicek.png")),
width = 600, height = 500, units = "px", pointsize = 15) # nastavení velikosti
{
layout(matrix(c(1,2), nrow = 1, byrow = TRUE), # dva obrázky vedle sebe
widths=c(5,1)) # šířkově v poměru 5:1 (druhý bude velmi hubený)
par(mar = c(4,4,2.5,0.5))
# barevné vykreslení hodnot funkce o dvou proměnných (heatmap)
image(x, y, z, main = c("f(x,y) = sin(x) * cos(y)"), bty = "n",
breaks = breaks, col = COLs, # kategorizace hodnot + barevné schéma
asp = 1) # zachová poměr x a y os 1:1
# legenda jako separátní obrázek
par(mar = c(4,0,2.5,3)) # horní a dolní okraje stejné, žádný vlevo, napravo delší
plot(0, 0, type ="n", # bty = "n", # NIC nekreslit, jen otevřít kreslící okno
xlim = c(0,1), ylim = c(-1,1), # rozsah y hodnot odpovídající hodnotám funkce
xaxs = "i", yaxs = "i", # žádné vnitřní rozšíření xlim a ylim hodnot
xaxt = "n", yaxt = "n", # bez os x a y
xlab = "", ylab = "") # žádné popisky os
axis(4, seq(-1, 1, length.out = 11), las = 2) # vlastní osa napravo
rect(xleft = 0, xright = 1, # obdélníky po celé šíři vykreslovací plochy
ybottom = breaks[-length(breaks)], # dolní hodnoty úzkých obdélníků
ytop = breaks[-1], # horní hodnoty úzkých obdélníků
col = COLs, border = NA) # barevné vyplnění obdélníků bez ohraničení
}
dev.off() # uzavření png - NEZAPOMENOUT!!!
y <- x <- seq(-2*pi, 2*pi, length.out = 201) # x-ové a y-ové hodnoty
z <- outer(sin(x), cos(y)) + outer(x, y)/20 # z = sin(x) * cos(y) + x * y / 20, každý s každým
dim(z)
(rz <- range(z))
barev <- 100
breaks <- seq(rz[1], rz[2], length.out = barev+1)
COLs <- hcl.colors(barev, palette = "YlGnBu")
png(file.path(dir_fig, paste0("image_sincos_plus_xy_", barev, "_barvicek.png")),
width = 600, height = 500, units = "px", pointsize = 15) # nastavení velikosti
{
layout(matrix(c(1,2), nrow = 1, byrow = TRUE), # dva obrázky vedle sebe
widths=c(5,1)) # šířkově v poměru 5:1 (druhý bude velmi hubený)
par(mar = c(4,4,2.5,0.5))
# barevné vykreslení hodnot funkce o dvou proměnných (heatmap)
image(x, y, z, main = c("f(x,y) = sin(x) * cos(y) + x*y/20"), bty = "n",
breaks = breaks, col = COLs, # kategorizace hodnot + barevné schéma
asp = 1) # zachová poměr x a y os 1:1
# legenda jako separátní obrázek
par(mar = c(4,0,2.5,3)) # horní a dolní okraje stejné, žádný vlevo, napravo delší
plot(0, 0, type ="n", # bty = "n", # NIC nekreslit, jen otevřít kreslící okno
xlim = c(0,1), ylim = rz, # rozsah y hodnot odpovídající hodnotám funkce
xaxs = "i", yaxs = "i", # žádné vnitřní rozšíření xlim a ylim hodnot
xaxt = "n", yaxt = "n", # bez os x a y
xlab = "", ylab = "") # žádné popisky os
axis(4, pretty(breaks), las = 2) # vlastní osa napravo
rect(xleft = 0, xright = 1, # obdélníky po celé šíři vykreslovací plochy
ybottom = breaks[-length(breaks)], # dolní hodnoty úzkých obdélníků
ytop = breaks[-1], # horní hodnoty úzkých obdélníků
col = COLs, border = NA) # barevné vyplnění obdélníků bez ohraničení
}
dev.off() # uzavření png - NEZAPOMENOUT!!!
Nyní si ukážeme, jak sestrojit 3D graf pomocí funkce
persp():
y <- x <- seq(-10, 10, length.out = 30)
f <- function(x, y){r <- sqrt(x^2+y^2); 10 * sin(r)/r}
z <- outer(x, y, f)
par(mar = c(1.5,0,0,0))
persp(x, y, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue",
ltheta = 120, shade = 0.75, ticktype = "detailed",
xlab = "X", ylab = "Y", zlab = "Sinc( r )", cex.axis = 0.8)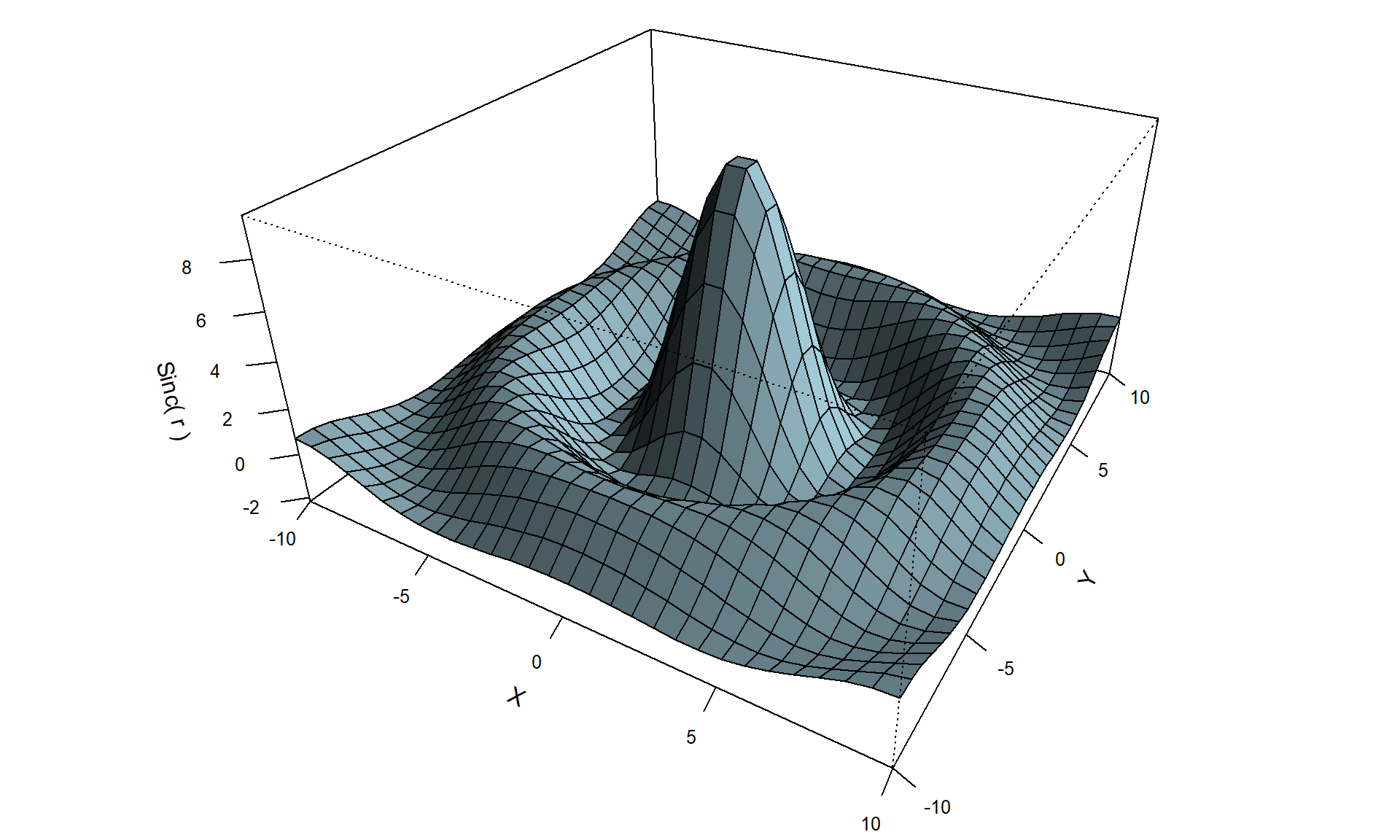
Hustota dvourozměrného normálního rozdělení:
library("mvtnorm")
x <- seq(-3, 3, length.out = 30)
y <- seq(-4, 4, length.out = 30)
Sigma <- matrix(c(1.2,0.6,0.6,1.8), nrow = 2, byrow = TRUE)
detSigma <- det(Sigma)
mu <- c(0,0)
# f <- function(x, y){ exp(-t(cbind(x,y) - mu) %*% solve(Sigma, cbind(x,y) - mu) / 2)/(2*pi)/sqrt(detSigma)}
f <- function(x, y){dmvnorm(cbind(x, y), mean = mu, sigma = Sigma)}
z <- outer(x, y, f)
par(mar = c(1.5,0,0,0))
persp(x, y, z, theta = 40, phi = 50, expand = 0.5, col = "olivedrab1",
ltheta = 120, shade = 0.75, ticktype = "detailed",
xlab = "X", ylab = "Y", zlab = "Hustota N_2", cex.axis = 0.8)
Nyní si ukážeme, jak vykreslit mapy. V obecném balíčku
maps nalezneme hranice států jako polygony jen pro mapu
celého světa a vybraných států světa (USA, Francie, …)
library("maps")
world <- map_data("world")
ggplot(data = world, aes(x = long, y = lat, group = group, bg = region)) +
geom_polygon() +
theme(legend.position="none")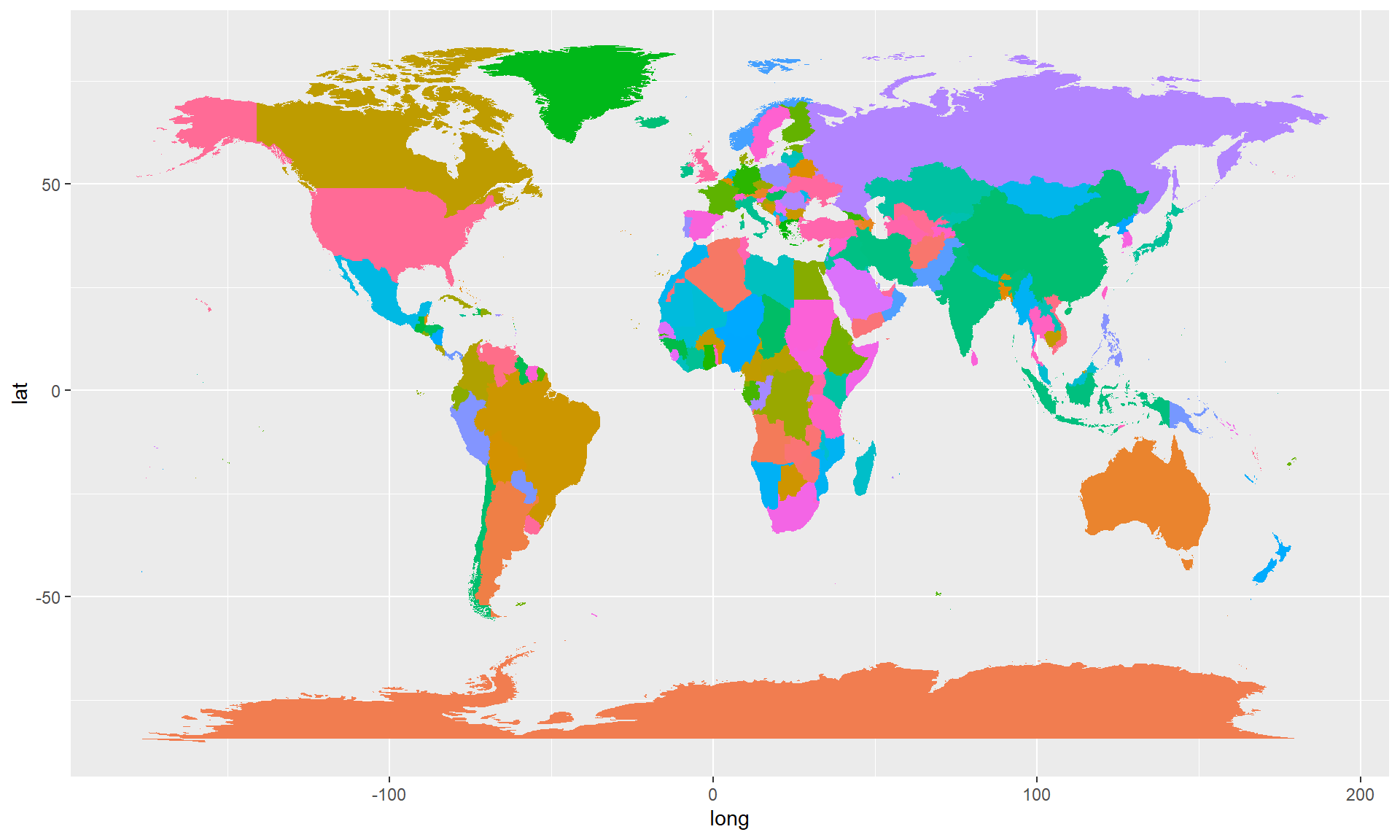
Existuje R-kový balíček s daty pro ČR. Najdete v něm třeba hranice krajů jako polygony.
library("RCzechia")
czechia <- kraje("low")
# czechia$KOD_CZNUTS3
# Nezaměstnanost - stav k 31.8.2025 dle ČSÚ - https://csu.gov.cz/jhc/mapa-podil-kraje
nezam <- c(3.50, 3.77, 3.77, 3.68, 5.33, 6.71, 5.06,
3.82, 3.56, 3.61, 5.02, 4.74, 3.73, 6.27)
names(nezam) <- c("PRA", "STC", "JHC", "PLZ", "KLV", "UST", "LIB",
"KRH", "PAR", "VYS", "JHM", "OLO", "ZLI", "MSK")
fnezam <- cut(nezam, breaks = seq(3.5, 7, by = 0.5), include.lowest = T)
colors <- heat.colors(nlevels(fnezam), rev = TRUE)
names(colors) <- levels(nezam)
par(mfrow = c(1,1), mar = c(0,0,2.5,0))
plot(st_geometry(czechia), col = colors[fnezam], main = "Nezaměstnanost v českých regionech")
legend("topright", levels(fnezam), fill = colors, bty = "n")
Obsahuje nejen kraje, okresy a řeky, ale i užitečné oblasti či sítě v rámci našeho území:
par(mfrow = c(1,2), mar = c(0,0,2.5,0))
chko <- chr_uzemi() %>% subset(TYP == "CHKO")
plot(st_geometry(chko), col = "forestgreen", main = "Chráněné krajinné oblasti")
plot(st_geometry(zeleznice()), col = "darkslategrey", main = "Železniční tratě")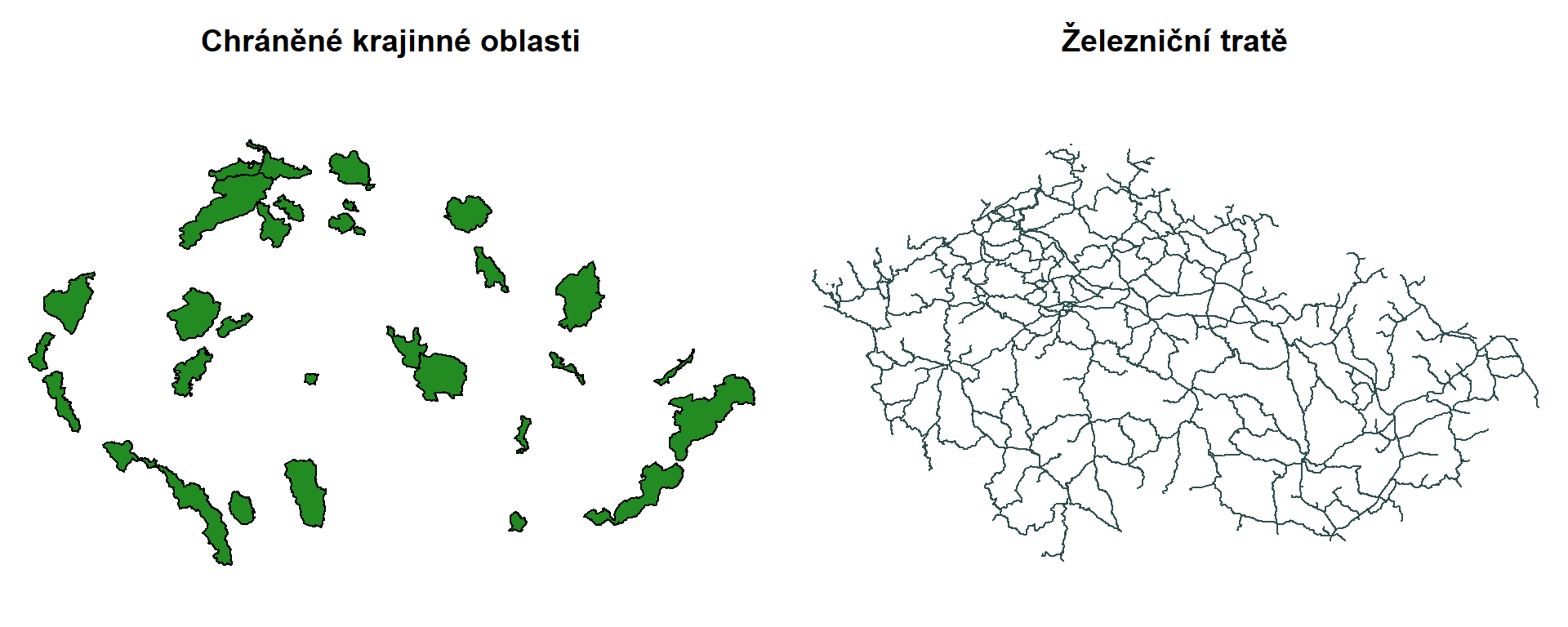 S útvary lze dělat různá prolínání a úpravy, ale to je nad naše
kapacity. Více o použití tohoto balíčku je k nalezení zde.
S útvary lze dělat různá prolínání a úpravy, ale to je nad naše
kapacity. Více o použití tohoto balíčku je k nalezení zde.
V tomto skriptu jsem se snažil ukázat spoustu různých barev
předdefinovaných v R. Pokud byste chtěli kompletní přehled, naleznete
jej v tomto dokumentu. Na tomto
webu lze také nalézt přehled Rkových barev spolu s konvertorem do
jiných formátů. Další palety barev jsou dostupné v balíčku
colorspace.
Úložky na procvičení
Vyřešte si to sami, aniž byste se dívali do řešení (úplně dole vespod skriptu).
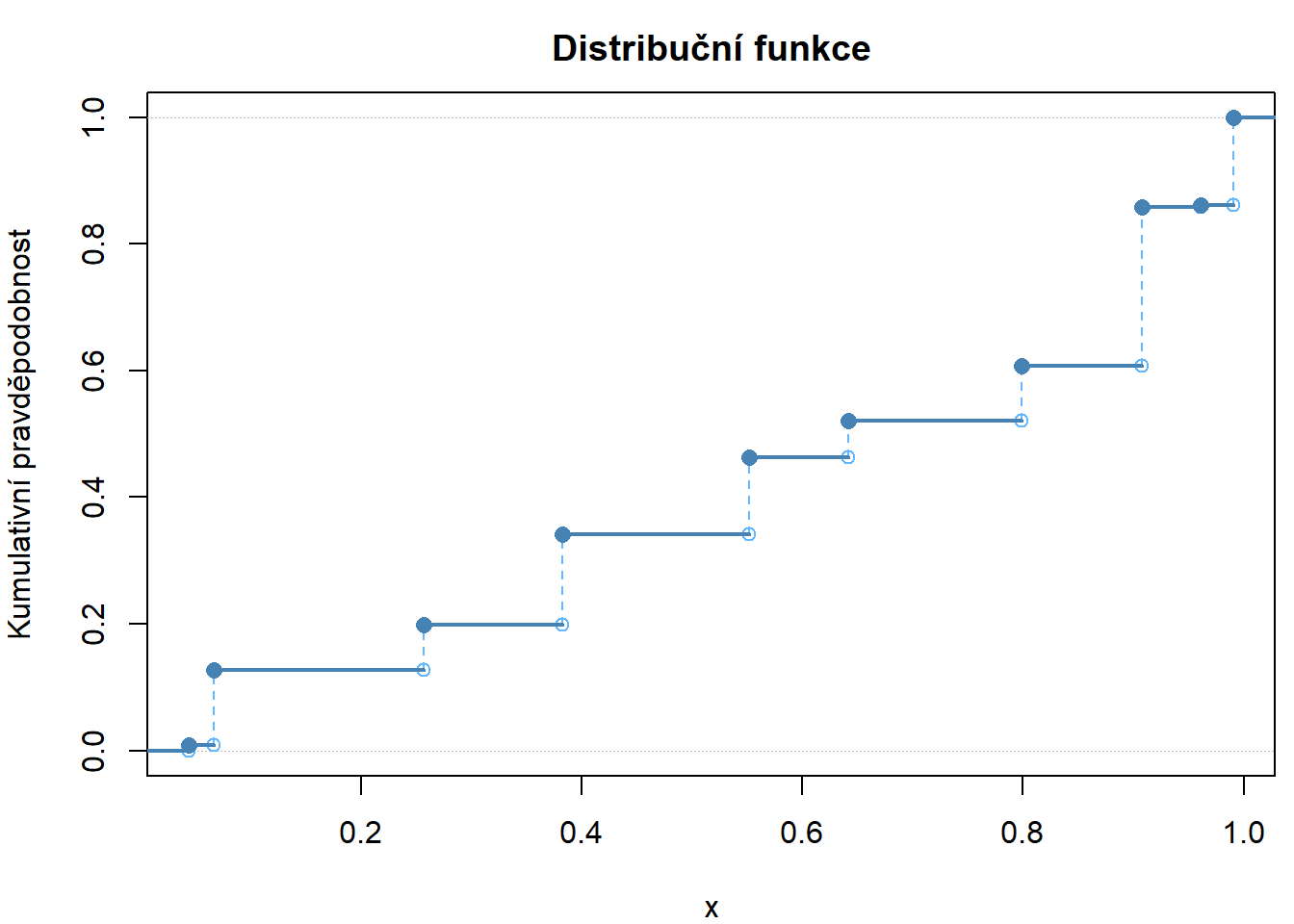
- Nakreslete si hezčí verzi distribuční funkce (neklesající, zleva spojitá):
- čárkované svislé vzestupy,
- tučně vodorovné hodnoty,
- plný bod, kde hodnota ve skoku,
- prázdný bod, kde dochází ke skoku,
- jakékoliv další kreativní vylepšení.
Nakreslete si obrázek terče, tedy soustředných kruhů o různých poloměrech s jiným podbarvením. Žádné osy, popisky ani okraje nejsou potřeba.
Vykreslete boxplot numerické proměnné, aniž byste použili funkci
boxplot. Používejtequantile,rect,segmentsapod.Vytvořge vlastní “počítadlový” diagram pro kategoriální proměnnou, kde četnost bude odpovídat počtu kuliček na počítadle (vodorovně zleva).
Podívejte se na dataset
?EuStockMarkets, který obsahuje 4 časové řady evropských akciových indexů, zakreslete je do jednoho obrázku jinými barvami. Jaké jsou mezi nimi vztahy? Jak vypadají autokorelační funkce těchto řad? Napočítejte pro každý index řadu diferencí v ceně oproti předchozímu pracovnímu dni. Vykreslete podvojné bodové diagramy a autokorelační funkce pro tyto diference.Pomocí datasetu
?chickwtsukázkově zakreslete, jaký je rozdíl ve výsledné váze kuřat při různé stravě. Typy krmiva si seřaďte dle mediánových hodnot váhy.Uvažte dataset
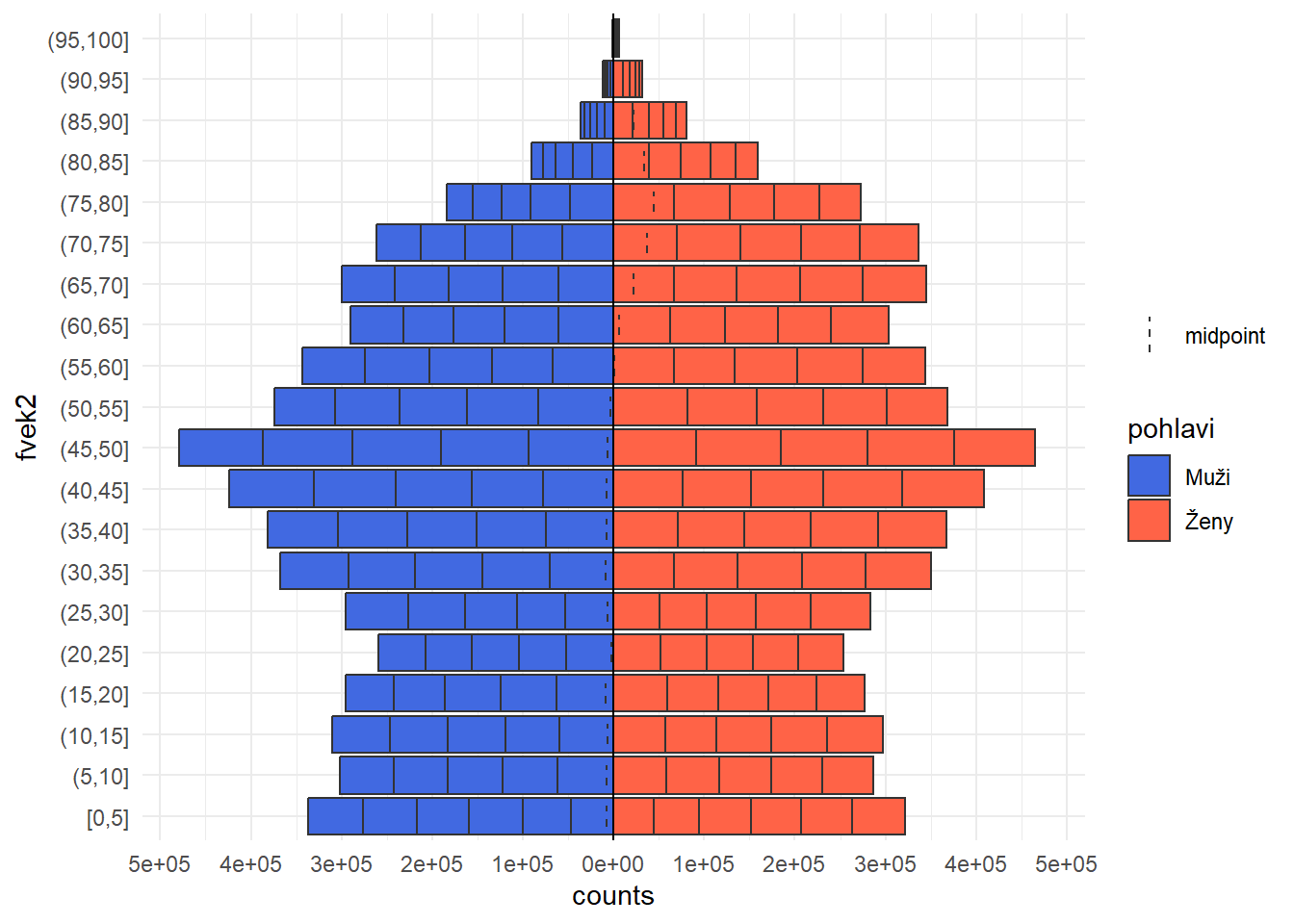
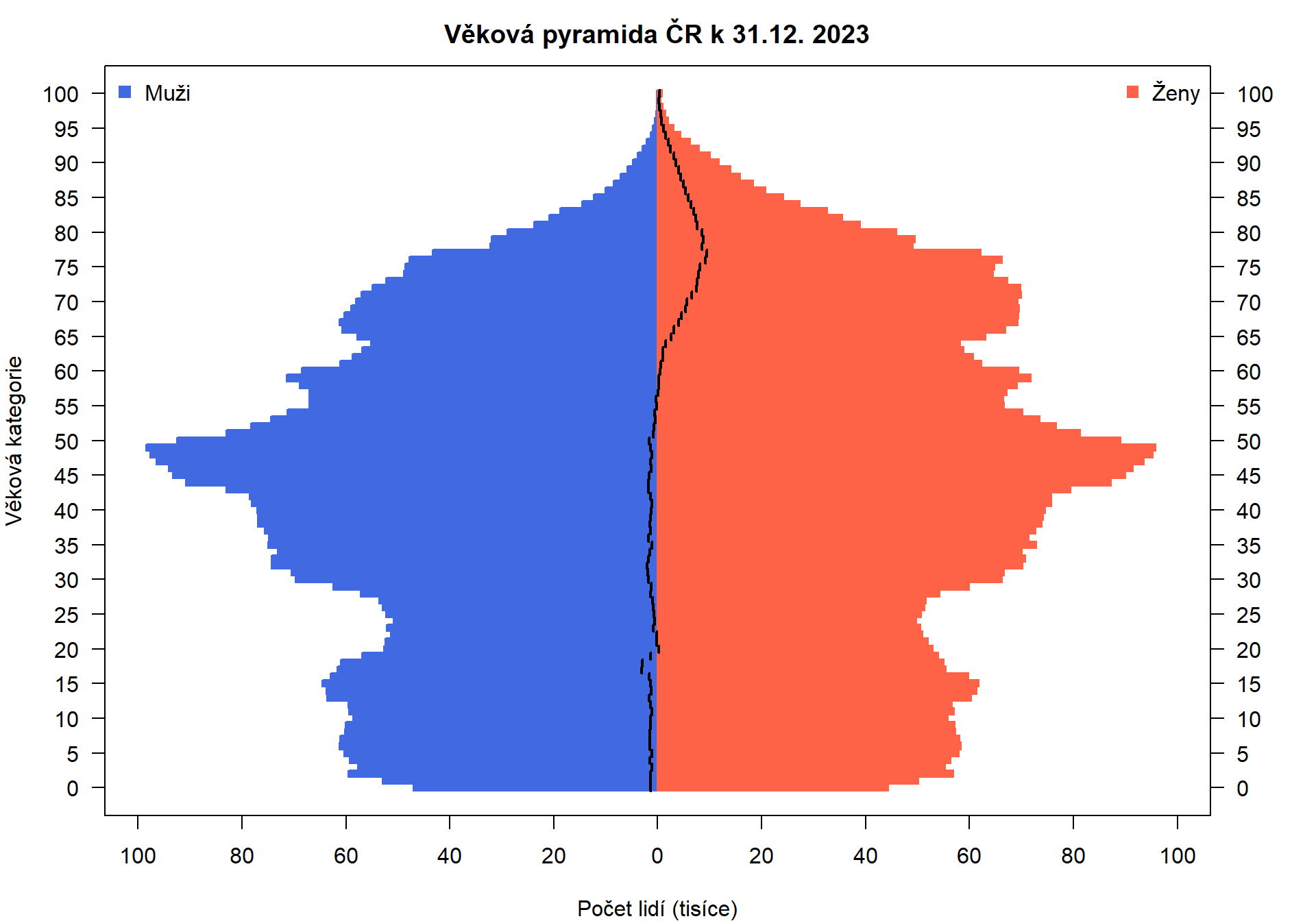
?HairEyeColorobsahující třírozměrnou tabulku, kde se studenti dělí do skupin podle barvy vlasů, barvy očí a pohlaví. Pomocí vhodných barev a obrázků zakreslete marginální četnosti, podvojné četnosti i celou tabulku.Věková pyramida. Stáhněte si z mých stránek data Českého statistického úřadu cr_1945_2023.xlsx, která obsahují počty mužů a žen v jednotlivých věkových kategoriích. Pro jeden zvolený rok vytvořte pomocí základních funkcí věkovou pyramidu, což jsou dva histogramy (pro muže a ženy) zády k sobě. Zde je návod, jak to vykreslit v Rku pomocí speciální knihovny:
library(readxl)
library(apyramid)
library(ggplot2) # apyramid funguje s touto knihovnou
data_dir <- file.path(dirname(getwd()), "data") # adresář s uloženými daty
veky <- 0:100
# Sloupec CC obsahuje data k 31.12. 2023
muzi <- read_excel(file.path(data_dir, "cr_1945_2023.xlsx"), range = "CC3:CC103", col_names = FALSE)
zeny <- read_excel(file.path(data_dir, "cr_1945_2023.xlsx"), range = "CC106:CC206", col_names = FALSE)
data <- data.frame(pohlavi = rep(c("Muži", "Ženy"), each = length(veky)),
vek = rep(veky, 2),
pocet = c(unlist(muzi), unlist(zeny)))
data <- transform(data,
fvek = factor(vek),
fvek2 = cut(vek, breaks = seq(0,100,by=5), right = TRUE, include.lowest = TRUE))
# Po roce
age_pyramid(data, age_group = fvek, split_by = pohlavi, count = pocet, horizontal_lines = FALSE) +
scale_fill_manual(values = c("Muži" = "royalblue", "Ženy" = "tomato")) +
theme_minimal()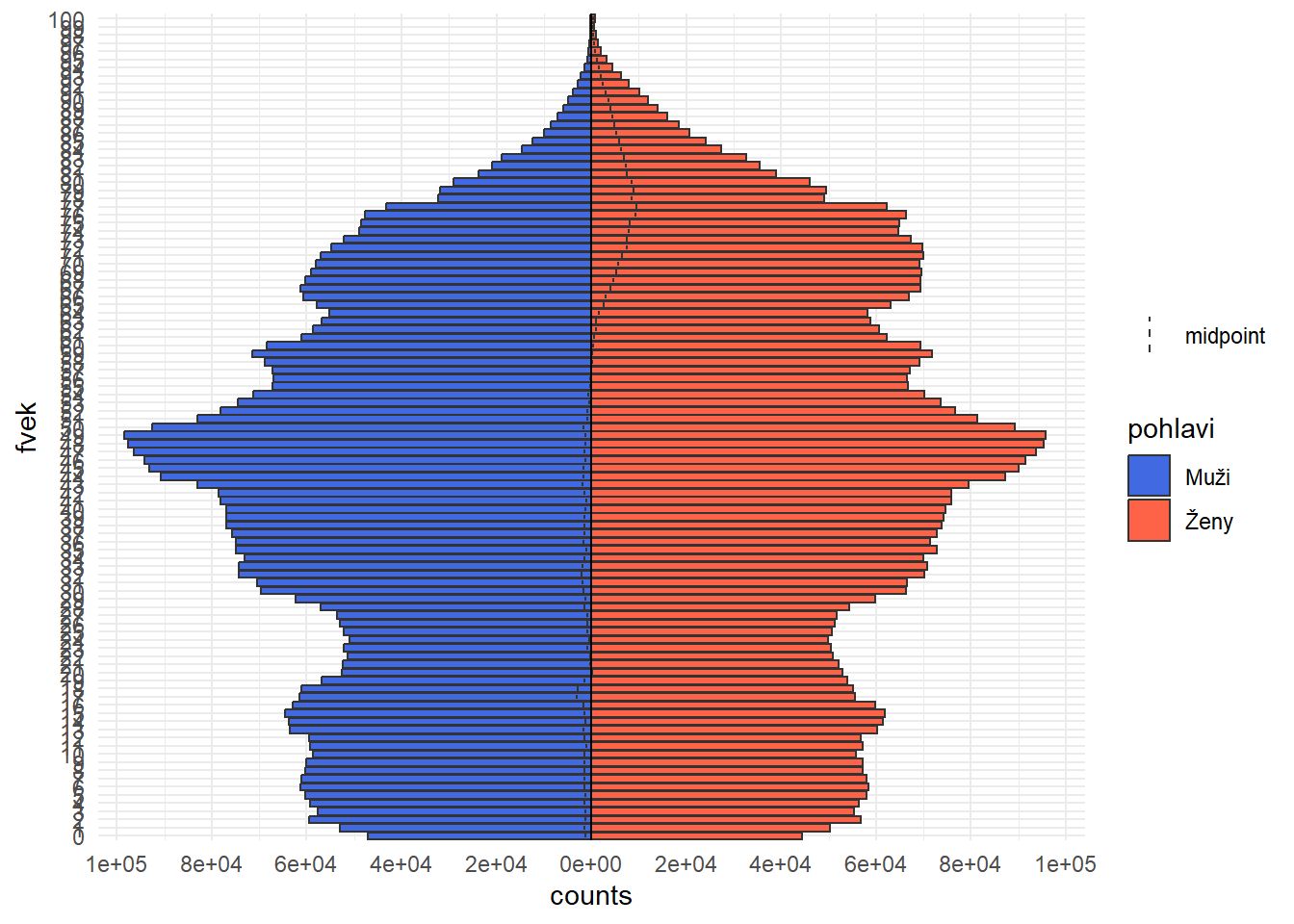
# Skupiny po 5 letech
age_pyramid(data, age_group = fvek2, split_by = pohlavi, count = pocet, horizontal_lines = FALSE) +
scale_fill_manual(values = c("Muži" = "royalblue", "Ženy" = "tomato")) +
theme_minimal()